
BERT (Bidirectional Encoder Representations from Transformers)
What is BERT ?
BERT is a pre-trained model released by Google in 2018, and has been used a lot so far, showing the highest performance in many NLP tasks. As the name suggests, BERT is a model that utilizes the Transformer structure described in the previous posting and has a characteristic of bidirectionality. BERT is a language model pre-trained with unlabeled text data such as Wikipedia and BookCorpus. From the English based model to the multilingual version using multilingual corpus can be implemented. BERT is built with a vast amount of unlabeled data, and it allows high performance when we adjust hyperparameters from other labeled tasks(e.g. classification) through additional training. This task is called ‘fine tuning’ and we will discuss about it with python code in later posting.
In this post, let’s learn more about the detailed structure of BERT.

(** Image from: https://wikidocs.net/115055)
Structure
Basic Architecture :

BERT is a model that utilized Transformer structure but used Encoder parts only, not Decoder parts. There are 2 major versions of the structure - Base version has a total of 12 layers consist of Transformer Encoder & Large version has a total of 24 layers. Large version has a larger d_model or a larger number of Self Attention Heads than the Base version. The number of parameters between the two models is about three times different (110M vs. 340M). FYI, most of the records set by BERT were made through BERT-Large. However, such a large model has been criticized for its computation problem. To compensate for these problems, ELECTRA was released. We will explain ELECTRA in detail in the next posting.
(**CAUTION : The explanations from now on are based on the Base model.)

BERT uses Contextual Embedding as ELMo or GPT-1 does. Since I’ve already explained how Transformer can reflect the context of corpus, I guess relating BERT to Contextual Embedding is not a difficult task. Parameter value d_model=768 (the number of hidden features of each sentence/word) is fixed, which means that all words are replaced by 768-dimensional embedding vectors and used as input to BERT. After an internal operation, BERT outputs a vector of 768 dimensions for each word equally. Simply put, since BERT itself is the combination of encoders, I don’t think it’s too hard to understand this principle.
After the computation of BERT, the output embedding becomes an embedding that reflects the context of the sentence, referring to all of the context. That is, the first input to BERT was simply a vector past the embedding layer, but the result of passing BERT becomes a vector with contextual information created by referring to all word vectors.
Details of BERT structure :
So far, we’ve learned about the overall structure of BERT. From now on, I will explain BERT by dividing the model into Input formatting part & Extracting (final) embeddings part. Before we start with the former part, let’s briefly look at the Special Tokens used in BERT in advance.
-
Special Tokens for BERT :
Suppose we want to get embedding of the example sentence ‘I love you’. Should I just embed ‘I’, ‘love’, and ‘you’ before putting it in BERT? No!! You can see tokens like [CLS] in the picture above, right? BERT requires special tokens to indicate the beginning and end of a sentence.
There are four main types of Special Tokens used in BERT.
1) [CLS] : Indicates the Beginning of a sentence
2) [SEP] : Indicates the End of a sentences
3) [UNK] : Indicates the Unknown piece/word in a sentence
4) [PAD] : Used for Padding
-
Ex 1) I love you. -> [CLS], I, love, you, [SEP]
Ex 2) I love you. But I hate strawberries. -> [CLS], I, love, you, [SEP], But, I, hate, straw, ##berries, [SEP]
** CAUTION : If you want to embed two sentences(inputs) to BERT, you can just distinguish between sentences with [SEP] instead of putting [CLS] in front of ‘But’. FYI, ‘##’ notation in ‘##berries’ is generated as a result of tokenization. I will explain about subword tokenization algorithms in separate posting, so wait a second!!
-
-
Input Formatting - Embedding layers:
From now on, let’s take a closer look at the Embedding layers. The role of Embedding layers is to convert the text input data into numerical one. So, you can regard this part as input formatting stage.
Embedding layer part consists of three layers - 1) Token embeddings, 2) Segment embeddings, 3) Position embeddings.
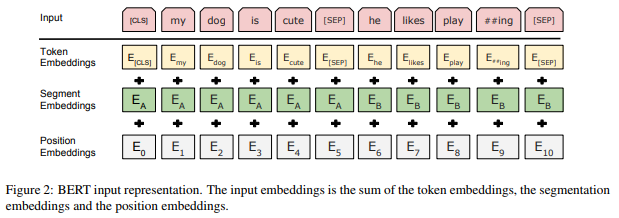
(** Image from: https://medium.com/@_init/why-bert-has-3-embedding-layers-and-their-implementation-details-9c261108e28a)_
Token embeddings : As alluded to in the previous section, the role of the Token Embeddings layer is to transform words into vector representations of fixed dimension. In the case of BERT, each word is represented as a 768-dimensional vector.
(** CAUTION: BERT package restricts the max length of tokens to 512, so be careful !!)
There are many methods that we can use to tokenize words/sentences - WordPiece, SentencePiece, BPE, etc. Of these, WordPiece tokenization is mainly used for BERT packages. If I explain all of these contents, I think the posting will be too long, so I will post about Subword algorithms separately. Now, let’s just point out that Token embeddings are done like the picture above.
Note that, as mentioned earlier, BERT package limits max length of token to 512, so if too long text data is given as input, only important tokens should be selected or only the middle part of the text should be cut to fit the format well.
Segment Embeddings : BERT is able to solve NLP tasks that involve text classification given a pair of input texts. An example of such a problem is classifying whether two pieces of text are semantically similar. The pair of input text are simply concatenated and fed into the model. So how does BERT distinguishes the inputs in a given pair? The answer is Segment Embeddings.
Suppose our pair of input text is (“I like cats”, “I like dogs”). Here’s how Segment Embeddings help BERT distinguish the tokens in this input pair :
(** CAUTION : BERT package only supports 2 segment representations - 0 or 1 !! So, do NOT try to embed more than 2 sentences by BERT simultaneously.)
The Segment Embeddings layer only has 2 vector representations. The first vector (index 0) is assigned to all tokens that belong to input 1 while the last vector (index 1) is assigned to all tokens that belong to input 2. If an input consists only of one input sentence, then its segment embedding will just be the vector corresponding to index 0 of the Segment Embeddings table.
Position Embeddings : BERT is not a model that operates as recurrent as RNN model, but has a bidirectionality property. Position embeddings help to maintain bidirectionality in BERT without operating in such a recurrent way. In other words, we combine the position embeddings of each word with the token & segment embeddings to reflect both the word-specific properties and the locational properties.
For example, assume there are 2 sentence inputs - ‘I love you’, ‘Love is pain’. Then, the final embedding values of the word ‘love’ in above two sentences will be different due to position embeddings although the word itself is the same. Position embeddings help the model to reflect the contextual meaning of each word.
To figure out more detail about how we can implement position embeddings, check the previous posting - ‘[Paper Review] Attention is all you need’. You can find specific way to complete position embeddings.
EXTRA - Attention Mask : If you practice BERT in practice, you will need an additional sequence input called Attention Mask. Attention Mask is an input that tells BERT to distinguish between actual words and padding tokens so that it does not needlessly focus on padding tokens when performing attention operations. This value has two values, 0 and 1, which means that the token is not masked because it is a real word, and the number 0 means that the token is a padding token, so it is masked. As shown below, you can create a sequence with a value of 1 for the location of the actual word & 0 for the location of the padding token to use it as another input to BERT.



=> Combining Representations : Token Embeddings & Segment Embeddings & Position Embeddings (**Dimension of all embeddings = (1,n,768) where n: # of tokens & 1: batch size) are summed element-wise to produce a single representation with shape (1,n,768) for one sentence, for example. Then, this input representation is passed to BERT’s encoder layer.
-
Extracting Embeddings - Transformer Encoders :
Actually, there is nothing much to explain in detail about Extracting Embeddings part. BERT uses 12 Transformer Encoders(12 layers for Base model) to extract final embedding values of a sentence. So, what you have to do is just format the input text by passing it through the Embedding layers, which were mentioned above, then let the Transformer Encoders to give us corresponding outputs. To learn more about the mechanism of Transformer in detail, go back to our blog and check out the previous posting about Attention.

So far, we’ve discussed about the structure of BERT and how it works. Although some details were omitted to make the posting easier to read, I will deal with some of the omitted topics in separate postings if it is necessary.
Now, let’s talk about pre-training methods of BERT and its pooling strategy & layer choices.
How to pre-train BERT ?
There are 2 methods for pretraining BERT - 1) Masked Language Model (MLM), 2) Next Sentence Piece (NSP).
1) Masked Language Model (MLM) :
For pre-training purposes, BERT randomly masks 15% of the input text that goes into an artificial neural network. And then, it let the artificial neural network predict these masked words. This is like drilling a hole in the words in the middle, and try to predict the words that will go into the hole. For example, just give the sentence ‘I go to [MASK] and buy bread and [MASK]’ and make them match ‘Super’ and ‘Milk’.
More precisely, not all [MASK] changes, but 15% of randomly selected words are applied again at the following rate:
1) [MASK]: 80% of the words are changed to [MASK]. Ex) The man went to the store → The man went to the [MASK]
2) Change word: Ten percent of the words are randomly changed. Ex) The man went to the store → The man went to the dog
3) Same : Let 10% of the words be the same. Ex) The man went to the store → The man went to the store
The word used to learn the masked language model is 15% of the entire word. The 12% used for learning predicts the original word after changing to [MASK]. 1.5% predict the original word after it changes randomly. 1.5% of the words have not changed, but BERT does not know if they are changed or correct. In this case, BERT also lets you predict what the original word is.
FYI, this [MASK] token is used only for pre-training and not for fine-tuning. By performing the task of matching the token, BERT develops the ability to grasp the context.
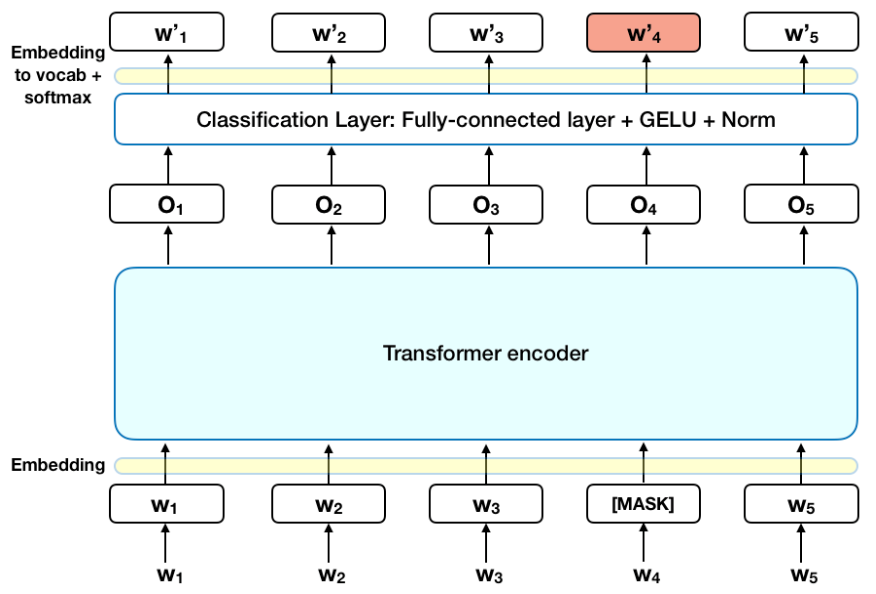
(** Image from : https://cdn-images-1.medium.com/max/2000/0*ViwaI3Vvbnd-CJSQ.png)
2) Next Sentence Piece (NSP) :
This pre-training task is performed because it is important to understand the relationship between two sentences, such as QA or Natural Language Inference (NLI) among several important NLP tasks. They are not captured in language modeling. Therefore, BERT perform the binarized next sentence preference task to determine whether the two sentences in corpus were attached immediately after the original corpus.
After giving two sentences, BERT trains them by matching whether the sentence is a continuous sentence or not. To do this, we give and train two sentences that are actually connected and two randomly attached sentences at a ratio of 50:50.
Ex)
Input =
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]LABEL =IsNextInput =
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]Label =NotNext
The [CLS] token is a special token added by BERT to solve classification problems. Whether the two sentences actually follow or not is determined by solving the binary classification problem in the output layer of the [CLS] token location.
** CAUTION : In BERT, MLM and NSP do not learn separately, but learn simultaneously by adding loss.

Pooling Strategy & Layer Choice
The BERT authors tested word-embedding strategies by feeding different vector combinations as input features to a BiLSTM used on a named entity recognition task and observing the resulting F1 scores.
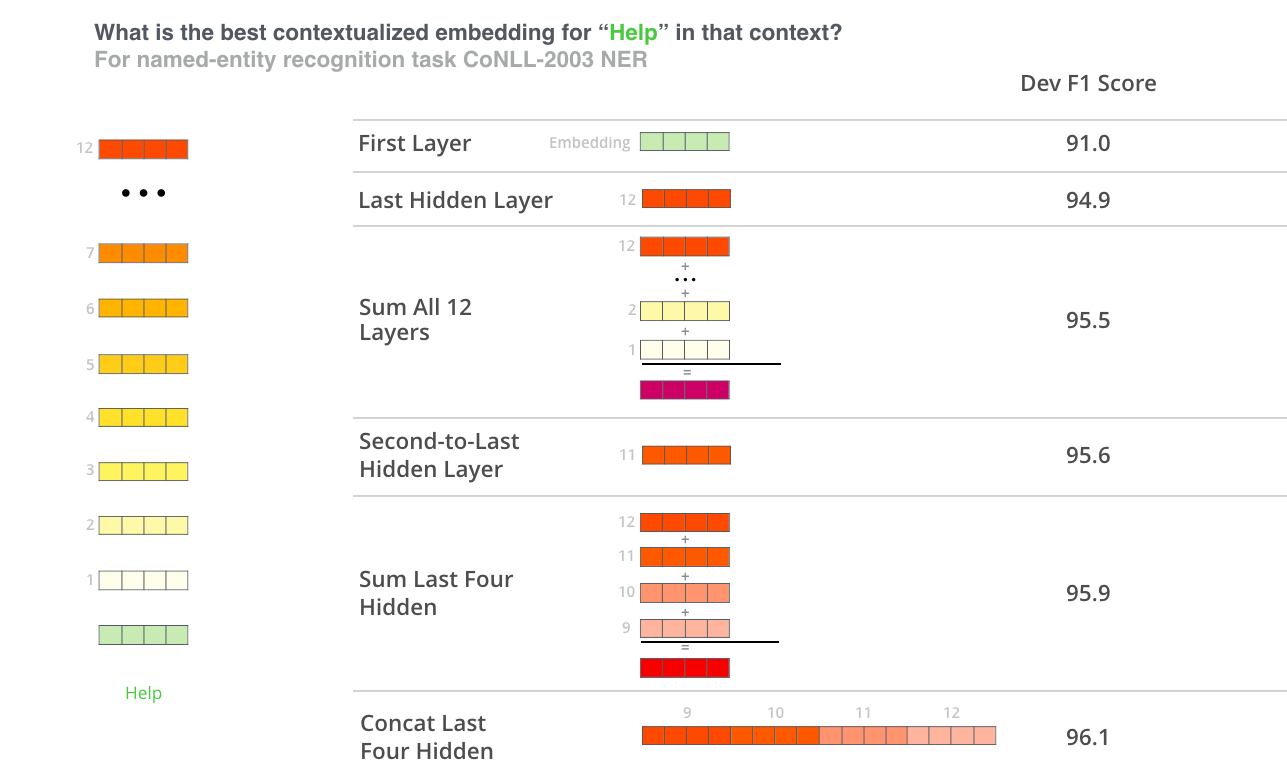
(** Image from: http://jalammar.github.io/images/bert-feature-extraction-contextualized-embeddings.png)
While concatenation of the last four layers produced the best results on this specific task, many of the other methods come in a close second and in general it is advisable to test different versions for your specific application: results may vary.
This is partially demonstrated by noting that the different layers of BERT encode very different kinds of information, so the appropriate pooling strategy will change depending on the application because different layers encode different kinds of information.
The method of generating word vectors by summing or concatenating the last 4 Layers, which is mentioned above, will be directly implemented through python code later.
So….
FINALLY, I’ve explained almost all of the main contents regarding BERT. Of course, there are some missing parts such as fine-tuning procedure of BERT. I will explain those in later postings in more detail (hopefully with code, too).
In order to understand BERT properly, you need to be familiar with various concepts such as Transformer, MLM, and NSP, so it will not be easy to understand it flawlessly. I hope this posting will be helpful for you all !!
Reference :
- https://arxiv.org/pdf/1810.04805.pdf
- https://medium.com/@init/why-bert-has-3-embedding-layers-and-their-implementation-details-9c261108e28a
-
https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/#32-understanding-the-output
- https://wikidocs.net/115055
- https://tmaxai.github.io/post/BERT/