
Text Clustering - BERT + Dimension reduction + KMeans
(CAUTION : You should pip install necessary packages such as transformers to run all codes below without error !!)
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import umap
Import dataset (Keyword sets - length:635609)
keyword = pd.read_csv('keyword.csv')
def clean_alt_list(list_):
list_ = list_.replace('[', '')
list_ = list_.replace(']', '')
list_ = list_.replace("'","")
list_ = list_.replace(',','')
return list_
keyword.keyword_list = keyword.keyword_list.apply(clean_alt_list)
lst_keyword = [x for x in keyword.keyword_list]

Extract Embedding values per keyword set using BERT
import torch
from transformers import BertTokenizer, BertModel, DistilBertModel
from tokenization_kobert import KoBertTokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
class Embed_Kor:
def __init__(self, sent, pretrain_ver='monologg/kobert'):
self.text = sent
self.ver = pretrain_ver
def tokenization_kor(self):
marked_text = '[CLS]' + self.text + '[SEP]'
tokenizer = KoBertTokenizer.from_pretrained(self.ver)
tokenized_text = tokenizer.tokenize(marked_text)
input_ids = tokenizer.convert_tokens_to_ids(tokenized_text)
att_mask = tokenizer.get_special_tokens_mask(input_ids[1:-1])
type_ids = tokenizer.create_token_type_ids_from_sequences(input_ids[1:-1])
return input_ids, att_mask, type_ids
def _transformer_kor(self):
model, vocab = get_pytorch_kobert_model()
input_ids, att_mask, type_ids = self.tokenization_kor()
input_ids = torch.LongTensor([input_ids])
att_mask = torch.LongTensor([att_mask])
type_ids = torch.LongTensor([type_ids])
sequence_output, pooled_output = model(input_ids, att_mask, type_ids)
final_embed = sequence_output[0]
return final_embed
if __name__=="__main__":
print('Transformer-Korean ver. ready')
class Embed_multi:
def __init__(self, sent, pretrain_ver='bert-base-multilingual-uncased', unit='sentence'):
self.text = sent
self.ver = pretrain_ver
self.unit = unit
def tokenization_multi(self):
tokenizer = BertTokenizer.from_pretrained(self.ver)
marked_text = '[CLS]' + self.text + '[SEP]'
tokenized_text = tokenizer.tokenize(marked_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
segment_ids = [1] * len(tokenized_text)
return indexed_tokens, segment_ids
def _transformer_multi(self):
model = BertModel.from_pretrained(self.ver, output_hidden_states = True)
indexed_tokens, segment_ids = self.tokenization_multi()
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segment_ids])
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensors)
hidden_states = outputs[2]
if self.unit == 'word':
## Stack all hidden states (outputs from 13 layers)
token_embeddings = torch.stack(hidden_states, dim=0)
## Squeeze the batch dimension (since we only deal with ONE sentence -> batch=1)
token_embeddings = torch.squeeze(token_embeddings, dim=1)
## Swap dimensions 0 and 1 ([layer,token,features=768] -> [token,layer,features=768])
token_embeddings = token_embeddings.permute(1,0,2)
## Summing last 4 layers
token_vecs_sum = []
for token in token_embeddings:
sum_vec = torch.sum((token[-4:]), dim=0)
token_vecs_sum.append(sum_vec)
return token_vecs_sum
elif self.unit == 'sentence':
token_vecs = hidden_states[-2][0]
sent_embed = torch.mean(token_vecs, dim=0)
return sent_embed
if __name__=="__main__":
print('Transformer-Multilingual ver. ready')
import pickle
embed_keyword = []
for idx, sent in enumerate(sents):
module = Embed_multi(sent)
res = module._transformer_multi()
res = res.numpy()
embed_keyword.append(res)
if (idx % 100) == 0:
with open('keyword_embed.pkl', 'wb') as f:
pickle.dump(embed_keyword, f)
print('Total {} sentences have been embedded.. Please wait a bit more.. :('.format(idx+1))
(** CAUTION: Depending on the size of data, it can take LOOOONG time !!)
Import toy data obtained by above method (length:1501)
with open('keyword_embed.pkl', 'rb') as f:
x = pickle.load(f)
data = np.asarray(x)

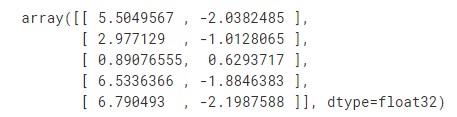
Dimension Reduction - 1) UMAP
reducer = umap.UMAP()
reduced_umap = reducer.fit_transform(data)
reduced_umap[:5,:]
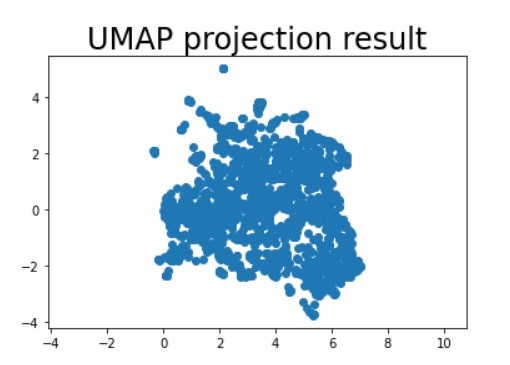
plt.scatter(
reduced_umap[:, 0],
reduced_umap[:, 1])
plt.gca().set_aspect('equal', 'datalim')
plt.title('UMAP projection result', fontsize=24)
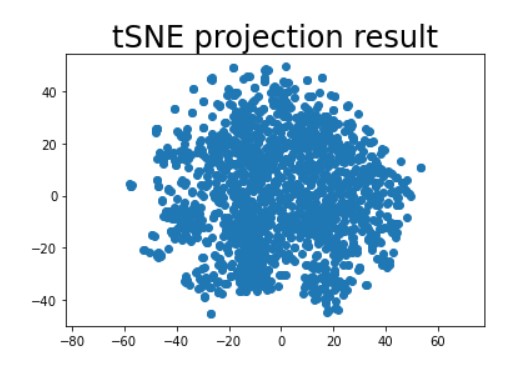
Dimension Reduction - 2) tSNE
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, metric='cosine')
reduced_tsne = tsne.fit_transform(data)
plt.scatter(
reduced_tsne[:, 0],
reduced_tsne[:, 1])
plt.gca().set_aspect('equal', 'datalim')
plt.title('tSNE projection result', fontsize=24)
KMeans
1) Full data version
from sklearn.cluster import KMeans
df = pd.DataFrame(data)
df['keyword_list'] = lst_keyword[:1501]
model = KMeans(n_clusters=30)
model.fit(data)
predict = pd.DataFrame(model.predict(data))
predict.columns = ['predict']
r = pd.concat([df,predict], axis=1)
cluster_keyword = r.groupby('predict')['keyword_list'].apply(lambda x: ' '.join(x))
pd.DataFrame(cluster_keyword)
-
Results :
There are some clusters that seem reasonable
-> ex) [세계여행 여행 행복 버스 지하철 친구 여행 사람 북유럽 버스 단편 퇴근 유럽여행….] / [시 이별 위로 제이팝 음악 일본 커피 문학 필사 시인….] / [사랑 연애 rain 사람 세상 남과여 슬픔 자작시 치유 접촉….] / [영화 매트릭스 리뷰 설리 연합뉴스 뉴스 디즈니 영화리뷰 ….] ….
BUT there are some clusters that seem awkward, too….
-> ex) [그림자 하이에나 도시 에세이 사진일기 아들 거리 가로등 시 기차 소년 아침….] / [인문학 소프트웨어 융합 프랑스 환경보호운동 기후변화 개발자 소프트웨어 정리….] / [시험 아침조회시간 취업 사회생활 결혼 출판 사회복지사 교육 드라마 방송 방송연예….] / [동아시아 면류 학 說 봉피 순면 반려동물 웹툰 올림픽 봄비 일러스트….] ….
-> Overall, not satisfying results….
2-1) Reduced data version - UMAP
model_umap = KMeans(n_clusters=30)
model_umap.fit(reduced_umap)
predict_umap = pd.DataFrame(model_umap.predict(reduced_umap))
predict_umap.columns = ['predict']
df_reduced_umap = pd.DataFrame(reduced_umap)
df_reduced_umap['keyword_list'] = lst_keyword[:1501]
r2 = pd.concat([df_reduced_umap,predict_umap], axis=1)
cluster_keyword_umap = r2.groupby('predict')['keyword_list'].apply(lambda x: ' '.join(x))
pd.DataFrame(cluster_keyword_umap)
- Results :
-> ex) [볼리비아 산타크루즈 미술관 톨레도 디트로이트 세월 시간 미켈란젤로….] / [문화극장 극장 소설 서평 페미니즘 인문학 소프트웨어 융합 사회생활….] / [자작소설 창작 드라마 방송 방송연예 학교 진화 다큐 작업기 사진 편집….] / [엄마 취향 효도 마약 서평 책소개 자전거 잠 맥주 마음 향기 사진일기 ….] / [사랑 연애 rain 감성에세이 사랑 첫사랑 취업 사회생활 결혼 세상 이해 생각….] / [그림일기 반려동물 웹툰 그림일기 웹툰 반려견 유튜브 운동영상….] / [영화 매트릭스 리뷰 설리 스타이즈본 영화리뷰 브런치무비패스 디즈니….] / [가을 커피 시 문학 필사 시인 사랑 명절 폭염….] / [목련꽃 아지랑이 동행 불꽃축제 불꽃 여의도 일상 단편….] / [여행 호주 국립공원 수원화성 수원화성박물관 유럽여행 여행에세이 엄마 미국해변….] ….
-> Overall, seem better than FULL version
2-2) Reduced data version - tSNE
model_tsne = KMeans(n_clusters=30)
model_tsne.fit(reduced_tsne)
predict_tsne = pd.DataFrame(model_tsne.predict(reduced_tsne))
predict_tsne.columns = ['predict']
df_reduced_tsne = pd.DataFrame(reduced_tsne)
df_reduced_tsne['keyword_list'] = lst_keyword[:1501]
r3 = pd.concat([df_reduced_tsne,predict_tsne], axis=1)
cluster_keyword_tsne = r3.groupby('predict')['keyword_list'].apply(lambda x: ' '.join(x))
pd.DataFrame(cluster_keyword_tsne)
- Results :
-> ex) [소설 서평 페미니즘 라이프스타일 츠타야 기획 슬픔 위로 손수건….] / [문화극장 극장 여행 혼자 날 서귀포 여행 인생 간이역 수의사 운동….] / [세계여행 여행 행복 유럽여행 여행에세이 엄마 여행 히치하이킹 남미여행 미국해변….] / [고백 자작소설 창작 드라마 방송 방송연예 학교 진화 다큐 작업기 꼬꼬마 일상 ….] / [더블린 아일랜드 석유에너지 베네수엘라 경제 크라쿠프 소금광산 유럽여행….] / [엄마 취향 효도 유형 관계 사람 필사 시기질투 인생 친구 직장 관찰 생각 기쁨….] / [음악 운동 헬스 고민 축구 캐나다 동호회음악 밴드 군대 영화….] / [사랑 연애 rain 감성에세이 사랑 첫사랑 취업 사회생활 결혼….] / [Linux 로그 상태 스마트폰 아이스크림 휴대폰 Linux 리눅스 설치….] / [캐릭터 드로잉 그림 비틀즈 음악 앨범 영화 매트릭스 리뷰 캠프 엑스레이 제이팝….] / [출판 사회복지사 교육 부동산경매 강제집행 개봉동 안락사 외국 수의사 장애엄마….] / [감정 마음 위로 주머니 동시 빵가게 생각 과거 무시 단상 여행….] ….
-> Overall, seem better than FULL version but not sure which to choose between UMAP or tSNE. I think analyzer should try several dimension reduction techniques and evaluate the best one !