
1. Stochastic Weight Average(SWA)
In many CV competitions, ensemble models are preferred by high rankers, definitely. However, due to high costs including time and resources, it often seems problematic to implement to real data.
Then, you had better try SWA which trains a single model, get number of snapshots after being sufficiently trained (like 75% of # of epochs) and ensemble them. As you can see below, SWA captures parameters at last three epochs and average them to an ensemble model. In this way, since you just need to train only a single model, you do not have to worry about time and computer resources compared to other huge ensembles.
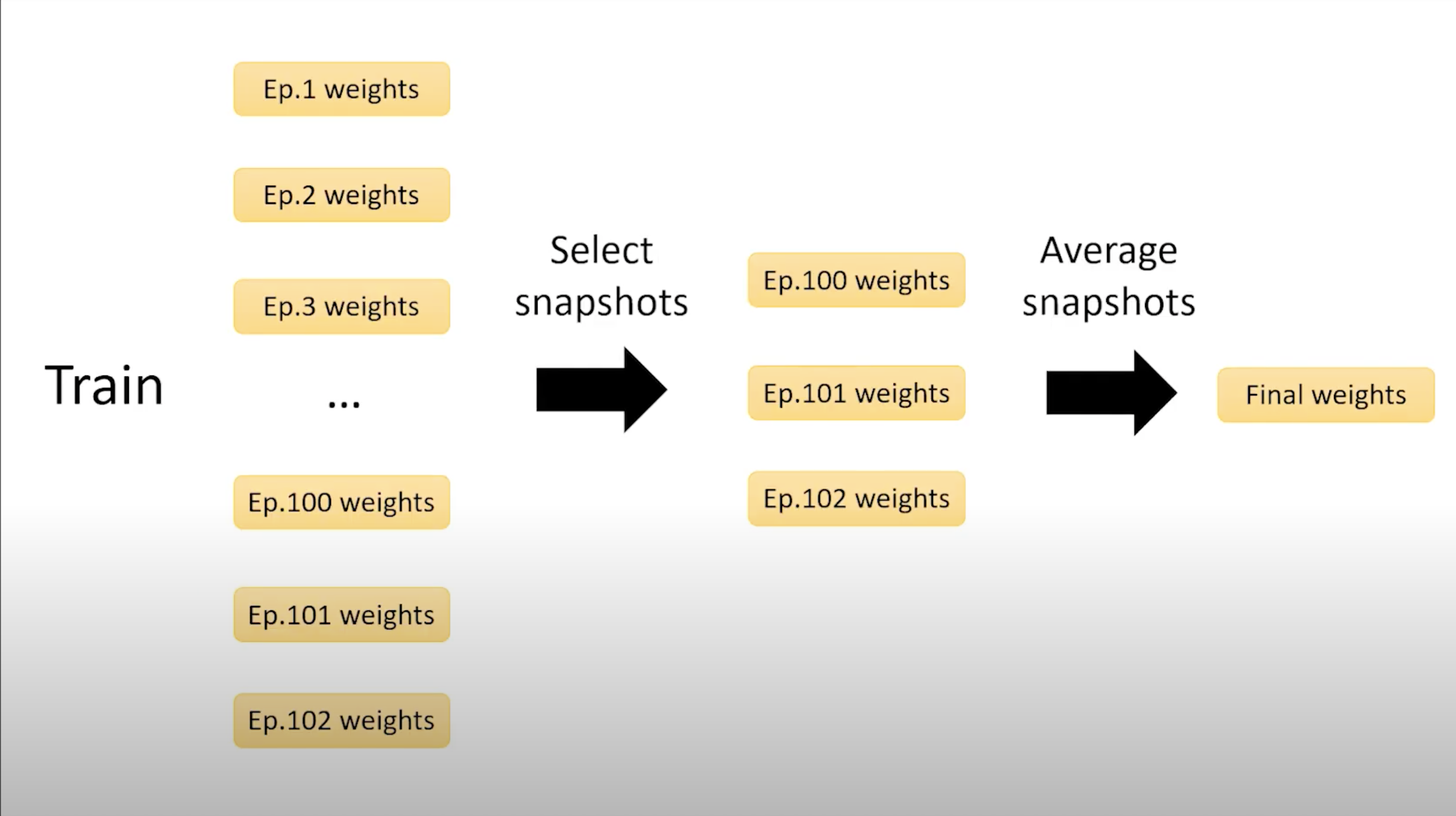
Not only have it advantages on efficiency, actually, SWA improves performace especially in CV and language modeling.
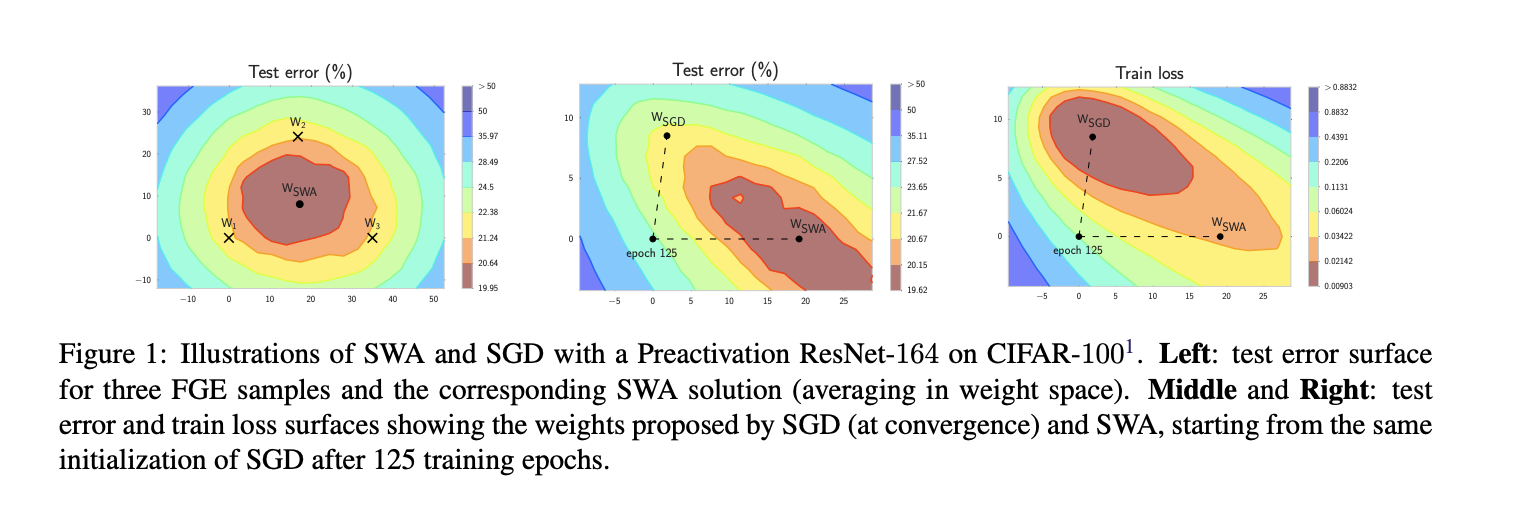
Through averaging model parameters, SWA leads model parameters to the central points. Even if it has larger train loss than SGD, it performs better in test data - generalization.
PyTorch provides packages for SWA:
from torch.optim.swa_utils import AveragedModel, SWALR
from torch.optim.lr_scheduler import CosineAnnealingLR
loader, optimizer, model, loss_fn = #define your own
swa_model = AveragedModel(model)
scheduler = CosineAnnealingLR(optimizer, T_max=100)
swa_start = 5
swa_scheduler = SWALR(optimizer, swa_lr=0.05)
for epoch in range(100):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
if epoch > swa_start:
swa_model.update_parameters(model)
swa_scheduler.step()
else:
scheduler.step()
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
# Use swa_model to make predictions on test data
preds = swa_model(test_input)
2. Data Augmentation
Absolutely, the more data you have, the better your deep learning model performs. We know that lots of popular datasets (mnist, cifar, etc) have tens of thousands of images.
What if we do not have ‘enough’ data - not sufficient for training?
Well, one thing you can do is ‘data augmentation’. You can add variants to exsting dataset, like flip, crop, rotation, etc. Your model will consider the original image and transformed versions distinctively.
Also, data augmentation is beneficial in the aspect of generalization. Especially images are not stable, I mean that the same thing would look differently under different conditions such as camera resolution, angle, light, etc. To provide image selections under wide range of conditions, your model can be more concrete, robust to those conditions.
In PyTorch, define transforms like below. For more options, visit pytorch docs :
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomAffine(degrees=10, scale=(0.9, 1.1)),
transforms.ToTensor(),
])
train_loader = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
valid_loader = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)

The above code alters the left picture to the right one.
3. CutMix
CutMix is one strategy of data augmentation. Cut out a squared part of an image and replace it with another image like below. As mentioned in data augmentation, this procedure makes the model be robust to new datasets, improving model performance eventually.

and the new lable for the CutMix image is $ y = \gamma * dog + (1-\gamma) * cat $.
In PyTorch:
import torch
import numpy as np
def rand_bbox(W, H, lam, device):
cut_rat = torch.sqrt(1.0 - lam)
cut_w = (W * cut_rat).type(torch.long)
cut_h = (H * cut_rat).type(torch.long)
# uniform
cx = torch.randint(W, (1,), device=device)
cy = torch.randint(H, (1,), device=device)
x1 = torch.clamp(cx - cut_w // 2, 0, W)
y1 = torch.clamp(cy - cut_h // 2, 0, H)
x2 = torch.clamp(cx + cut_w // 2, 0, W)
y2 = torch.clamp(cy + cut_h // 2, 0, H)
return x1, y1, x2, y2
def cutmix_data(x, y, alpha=1.0, p=0.5):
if np.random.random() > p:
return x, y, torch.zeros_like(y), 1.0
W, H = x.size(2), x.size(3)
shuffle = torch.randperm(x.size(0), device=x.device)
cutmix_x = x[shuffle]
lam = torch.distributions.beta.Beta(alpha, alpha).sample().to(x.device)
# lam = torch.tensor(np.random.beta(alpha, alpha), device=x.device)
x1, y1, x2, y2 = rand_bbox(W, H, lam, x.device)
cutmix_x[:, :, x1:x2, y1:y2] = x[shuffle, :, x1:x2, y1:y2]
# Adjust lambda to match pixel ratio
lam = 1 - ((x2 - x1) * (y2 - y1) / float(W * H)).item()
y_a, y_b = y, y[shuffle]
return cutmix_x, y_a, y_b, lam
4. Test Time Augmentation(TTA)
TTA is also one way of data augmentation, but on test dataset. In addition to this, TTA creates several altered images from an original image, make a prediction for each altered target image then averages those predictions to find the maximum value (for classification).
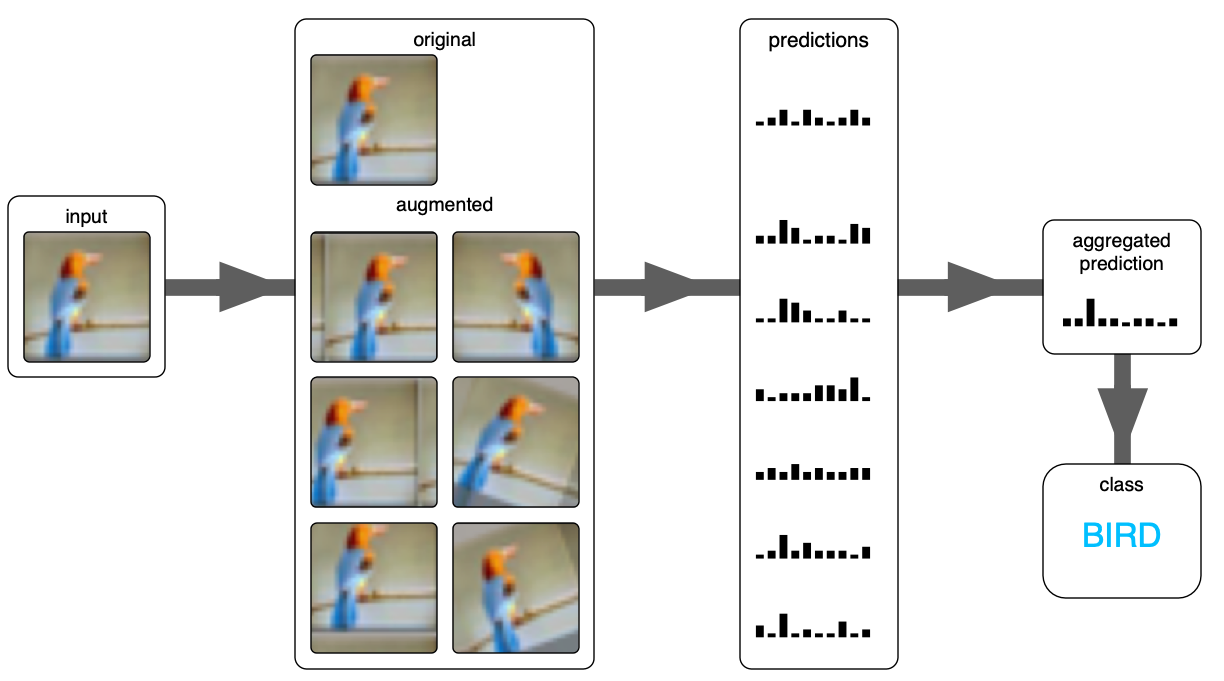
For implementation in PyTorch, read a package description.
Reference
- https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced
- Pytorch SWA tutorial
- https://www.youtube.com/watch?v=Haj-SRL72LY&t=121s&ab_channel=YouHanLee
- https://sh-tsang.medium.com/paper-cutmix-regularization-strategy-to-train-strong-classifiers-with-localizable-features-5527e29c4890
- https://towardsdatascience.com/test-time-augmentation-tta-and-how-to-perform-it-with-keras-4ac19b67fb4d
- https://inspaceai.github.io/2019/12/20/Test_Time_Augmentation_Review/
- https://machinelearningmastery.com/how-to-use-test-time-augmentation-to-improve-model-performance-for-image-classification/
- https://stepup.ai/test_time_data_augmentation/
- https://www.nature.com/articles/s41598-020-61808-3