
Today, I will review a paper that first integrated the idea of latent variables with deep learning. The original paper was written by Heng-Tze Cheng et al. from Google Inc (Google). First introduced in 2016, this method was successfully implemented in Google Play app store (though it now seems to have been replaced or enhanced by DeepMind’s sota DL methods. we will go over that later ). You can also find open-source implementation in tensorflow. Before going deeply into this paper, let’s go over how Wide & Deep method came to be.
Background Information
Keeping track of frequent co-occurring feature combinations is important in quality of recommendation. (By features, I mean user, item, and contextual information.) This co-occurrence is termed as cross-product features. Cross-product terms can incorporate non-linear interactions between features. For example, system memorizes interaction of color and brand when recommending sneakers. However, (generalized) linear models conveys some difficulties in modeling interaction terms as they have to be manually included by the author. Thus, hidden interactions are often disregarded. To overcome such limitations, Factorization Machines(FM) arose as an effective method to model up to degree-2 interactions as inner product of latent vectors, and showed very promising results.
Another important part in recommendation system is whether unseen, new user-item interactions can be modeled. FM can generalize to unseen interactions by learning low-dimensional latent vector representation of users and items. Deep learning recommendation methods also emerged to further improve representation of features through low-dimensional embedding layers. Another advantage of deep learning method is that high-order cross-product terms can be added to include sophisticated relationships between features.
A hybrid approach, Wide & Deep method achieves both goals, by memorizing wide cross-product features, and generalizing unseen feature interactions through low dimensional embeddings.
Paper Review
Two important concepts appear in this paper : Memorization and generalization
Memorization - Wide - past interactions
“Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.”
The wide component is generalized version of linear model,
where x denotes a vector of features and w is a vector of model parameters. One important thing is that x is composed of not only raw featurs, but also transformed features g(x) to include feature interactions. Note that there is no neural network in this part and limitation of having to identify specific features to be “crossed” using domain knowledge still exists.
Generalization - Deep - unseen interactions
“Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.”
Another problem of cross-product modeling is that it fails to consider feature pairs that have not appeared in training data. Systems based on memorization soley would make the suggestions limited and boring. Users might want to find new delights from new items. Deep component effectively learns low embedding representations of features to generalize user-item interactions. Categorical features can also be embedded. Embedded features are then passed to hidden layers and output layers just as any other feed-forward neural networks.
Joint learning
Key advantage of this method is that wide part and deep part are jointly learned, rather than simple ensemble. A weighted sum of the two components’ output log odds are fed into one common logistic loss function for training. As a result, parameters of both components are updated simultaneously. This is different from ensemble method, where final predictions are linearly combined to produce one final prediction
Model Structure
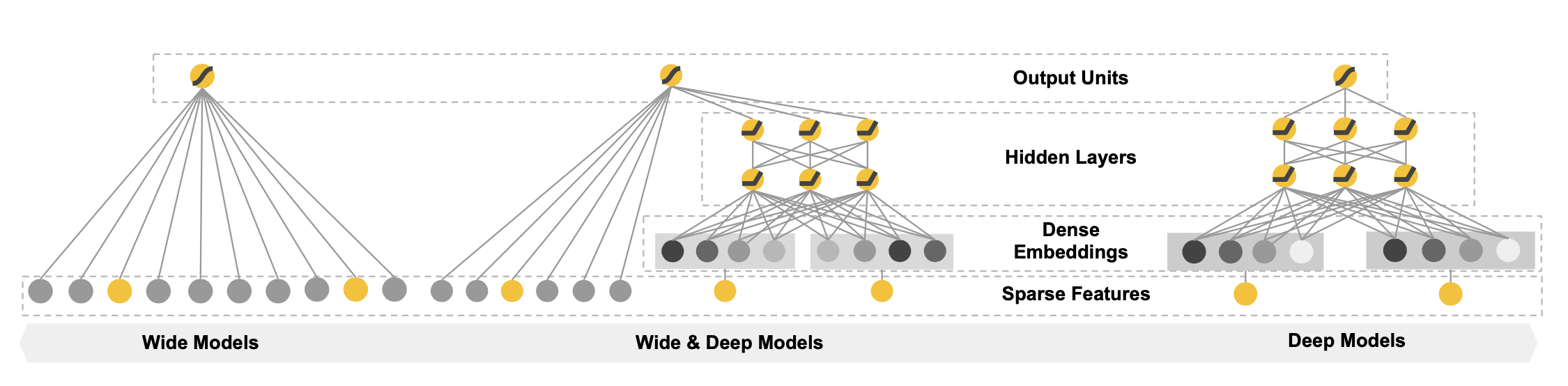
Further Improvements
There were consistent studies on applications of deep-learning-based recommendation systems after this paper was proposed. Some examples are Production-based-Neural-Network(PNN,2016) and Factorization_Machine-supported-Neural_Network(FNN,2017). However, these fail to capture low-order interactions that Wide & Deep method could. DeepFM(2017) was created to overcome limitation of feature-engineering in Wide & Deep method.
References
- H. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, G. Anderson, G. Corrado, W. Chai, M. Ispir, R. Anil, Z. Haque, L. Hong, V. Jain, X. Liu, and H. Shah, “Wide & deep learning for recommender systems,” CoRR, vol. abs/1606.07792, 2016.
- S. Rendle, “Factorization machines,” in ICDM.
- Y. Qu, H. Cai, K. Ren, W. Zhang, Y. Yu, Y. Wen, and J. Wang, “Product-based neural networks for user response prediction,” CoRR, vol. abs/1611.00144, 2016.
- H. Guo, R. Tang, Y. Ye, Z. Li, and X. He, “Deepfm: A factorization- machine based neural network for CTR prediction,” in Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intel- ligence, 2017, pp. 1725–1731.
- Guo, H., Tang, R., Ye, Y., Li, Z., & He, X. (2017). DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247
Also refer to https://paperswithcode.com/task/recommendation-systems#code for SOTA recommendation systems.