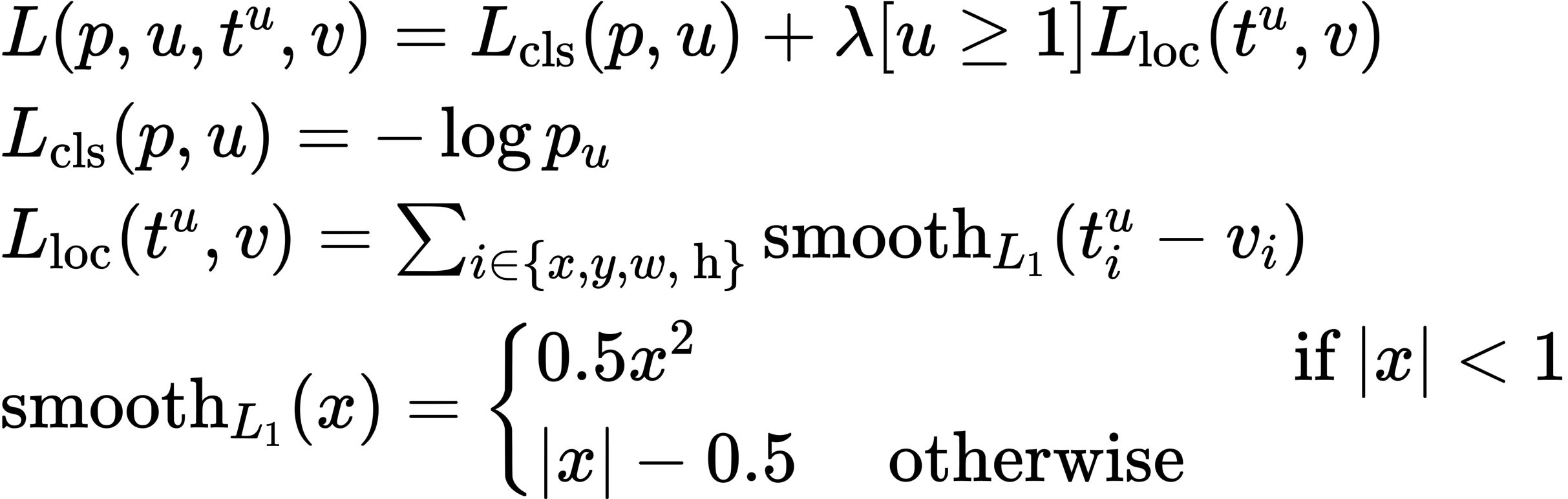We know that the R-CNN opened a new prospect in the field of computer vision, but it is time and resource consuming and a multi-stage pipeline (three stages: ConvNet, SVM, bounding box regressor) - not end to end.
Fast R-CNN is proposed to solve the above problems :running_man:
To begin with, its architecture first.
- Inputs to be an entire image and a set of object proposals (via selective search)
- Create a conv feature map using the whole image
- Run through a region of interest (RoI) pooling layer and extract a fixed-length feature vector from each object proposal
- Through FC layers in series, we will get two outputs:
- softmax probability for classifying into K+1 classes (1 for background)
- real-valued numbers for estimating four points of a bounding box regression
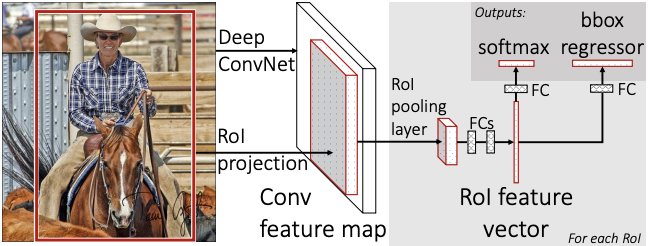
Focus on difference between R-CNN and Fast R-CNN.
The first thing you might be unfamilar with is RoI Pooling layer. Considering the R-CNN structure, since the input size for the last FC layer should be fixed, R-CNN warps all pixels in a tight box before computing CNN features.
However, what if adjusting the image size after all the CNN process?
RoI Pooling Layer
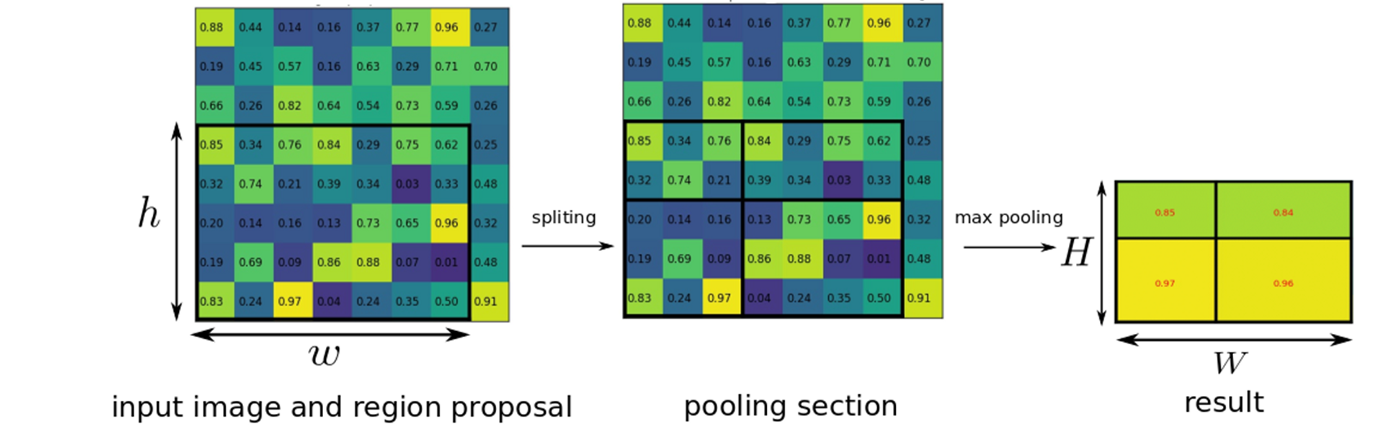
After creating a conv feature map (step 2), the RoI pooling layer uses max pooling on region proposals (black box with h x w in the left side) to convert the image size into a fixed size of H x W (in the right side of the picture). Whatever the size of input image is, the RoI pooling layer extracts a fixed-length feature vector needed for FC layers.
RoI max pooling splits RoI with h x w into an output of H × W that is consisted with some sub-windows of approximate size h/H × w/W and then take a max-pooling to each sub-area. Assume that h=5, w=7, H=2 and W=2. Then the area for each sub-window (look at four black boxes in the middle) would be 2x2, 3x3 like that.
Remember that in R-CNN, we need to process CNN for every region proposal. 3,000 times CNN computations for 3,000 region proposals. However, Fast R-CNN only needs to compute CNN once, excelerating the whole procedure eventually.
Next thing to consider is…
End-to-end learning with multi-task loss
R-CNN has a multi-stage pipeline consisting of three modules: ConvNet, SVM and bounding box regressors. It is controversial that end-to-end structure always performs better than multi-stage pipeline, but clearly it is straight-forward and based on what deep learning is and should be. (Of course, it performs well in many cases)
Fast R-CNN defines Multi-task Loss so that it achieves end-to-end learning. The multi-task loss is a combination of the classification loss and bounding box regression to jointly train.