
In this post, I aim to address potential problems with RNN based neural machine translation (NMT) models and introduce a solution this paper proposed.
Introduction / Related Works
This paper was written in 2015, just shortly after the area of neural machine translation (NMT) first came out. Before then, machine translation was mostly statistic-based (SMT), which is composed of translation and language models. However, SMT had some drawbacks such as inability to function with abnormal words such as slangs or idioms. NMT on the other hand was more fit for new types of phrases. The earliest NMT methods were mostly RNN-based encoder decoder models (Seq2Seq). A potential issue with these models is that it encodes words into a fixed size vector. If the input sentence is too long, longer than training corpus, it might not compress all the information.
Align?
: Aligning is matching the original language words to translated language words to create translation memory. ex) apple - 사과 / car - 자동차
Approach
To address the above problem, this paper extends the encoder-decoder model so that the model learns to align and translate jointly. The proposed model (soft-) searches for the parts of source sentence (original language input) that contain the most relevant information for the target word (translated word). What distinguishes this method from other methods is that it does not encode the whole sentence into fixed size vector. Instead, input sentence is encoded into a sequence of vectors and only a subset of these vectors is chosen for decoding procedure.
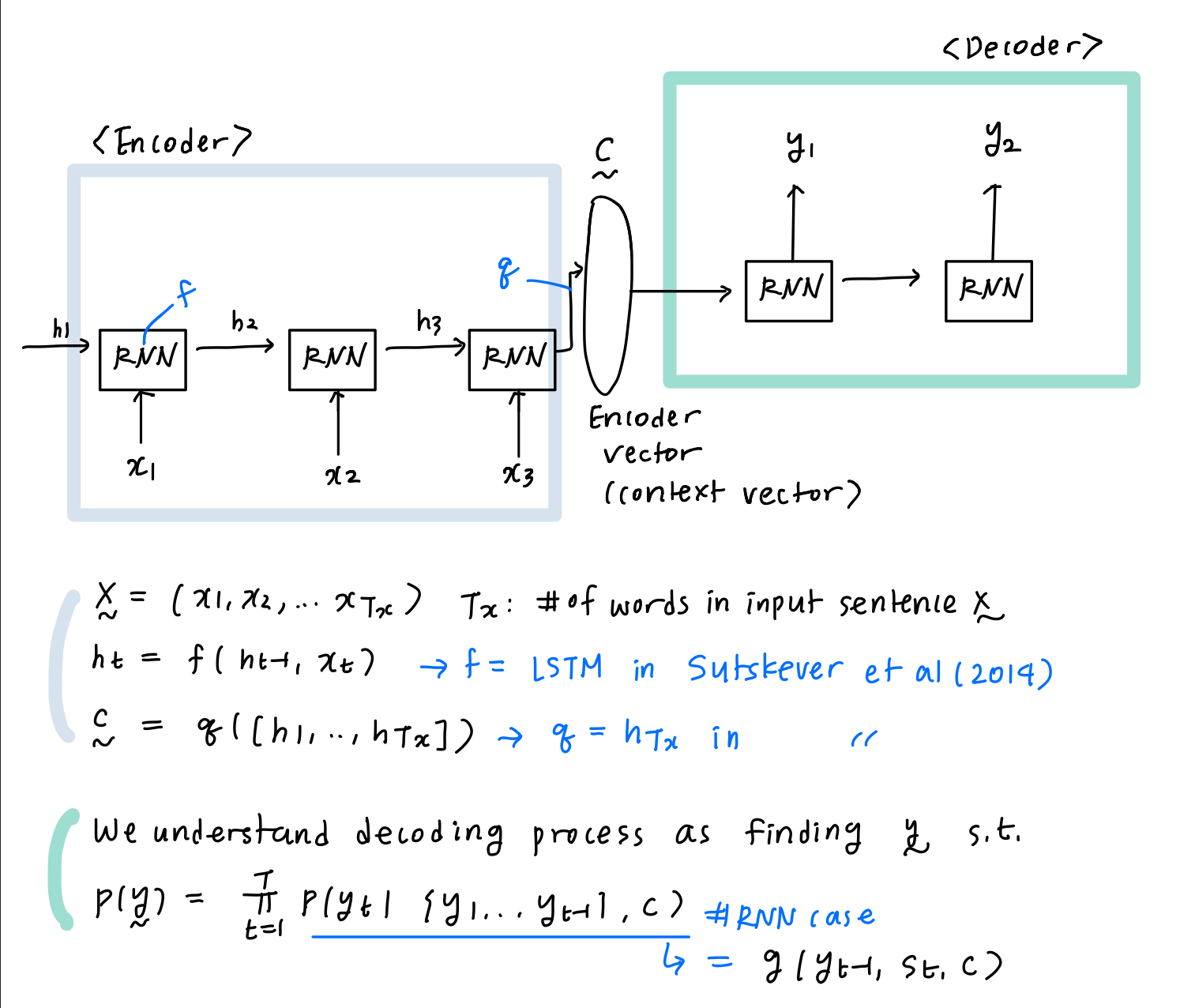
Basic RNN encoder-decoder - RNNencdec
Prior research (Sutskever et al.) has shown promising results on NMT by using LSTM units on RNN based machine translation. Let’s first go over the framework of RNN encoder-decoder.
Novel RNN encoder-decoder - RNNsearch
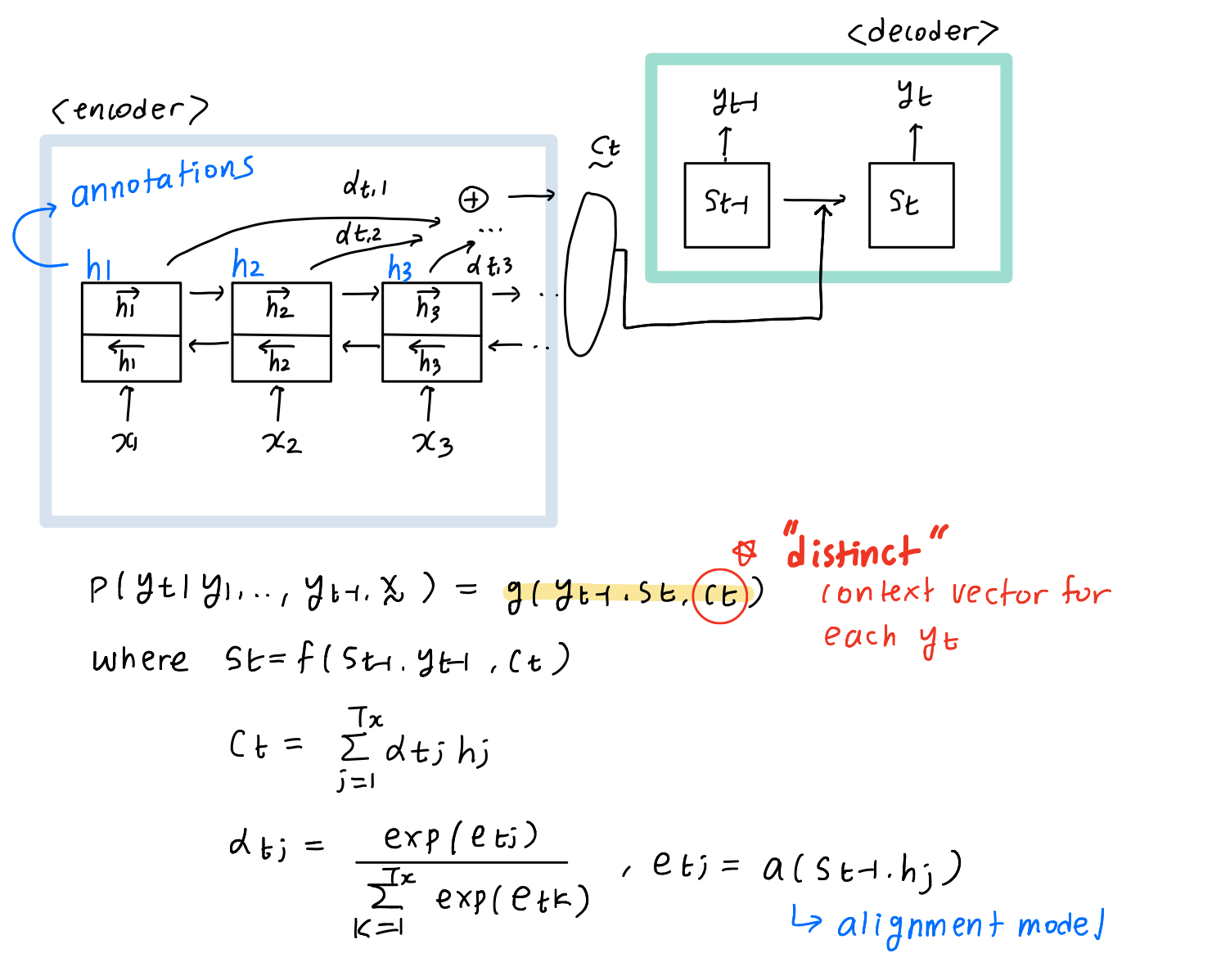 The big difference with the original model is that distinct context vector is obtained for each target word $y_{t}$. The alignment model $e_{tj}$ scores how well the inputs around position $j$ and the output at position $t$ matches (recall that aligning is matching source word and target word). This paper parametrizes alignment model $a$ as feedforward neural network which is jointly trained with all other components of this model. (This is why this model is said to align and translate jointly)
The big difference with the original model is that distinct context vector is obtained for each target word $y_{t}$. The alignment model $e_{tj}$ scores how well the inputs around position $j$ and the output at position $t$ matches (recall that aligning is matching source word and target word). This paper parametrizes alignment model $a$ as feedforward neural network which is jointly trained with all other components of this model. (This is why this model is said to align and translate jointly)
Interpretation of Parameters
We can interpret $a_{tj}$ as the probability that target word $y_{t}$ is aligned to source word $x_{j}$. Since context vector $c_{t}$ is a weighted sum of annotations $h_{j}$ with weights $a_{tj}$, it can be interpreted as expected annotation. Thus, the decoder part decides part of input sentence x to pay attention to, which also follows our intuition.
Evaluation / Conclusion
The proposed model was compared to original RNN encoder-decoder model by (Cho, 2014a) on English-French parallel corpora. Each method is tested on both corpus with sentence length up to 30 and 50. Minibatch SGD was used for training. Test score is BLEU.
The performance of RNNencdec dramatically dropped as sentence length increased while RNNsearch showed better performance in both tasks.
References
- Cho, K., van Merrienboer, B., Gulcehre, C., Bougares, F., Schwenk, H., and Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Empiricial Methods in Natural Language Processing (EMNLP 2014). to appear.
- Cho, K., van Merrienboer, B., Bahdanau, D., and Bengio, Y. (2014b). On the properties of neural machine translation: Encoder–Decoder approaches. In Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. to appear.
- Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS 2014).