
Text Understanding with the Attention Sum Reader Network
Introduction
There are several large cloze-style context-question-answer datasets which was introduced 4~5 years ago - the CNN, Daily Mail news data, and the Children’s Book Test. Thanks to the introduction to these large datasets, it became easier to associate text comprehension task to deep-learning techniques that seem to outperform all alternative approaches. This paper presents a simple model that uses attention to directly pick the answer from the context as opposed to computing the answer using a blended representation in similar models.
Cloze-Style questions
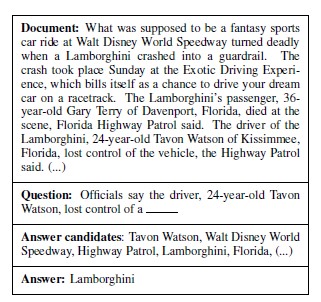
Cloze-style questions are the questions formed by removing a phrase from a sentence.
One way of testing the level of text understanding is simply to ask the system questions for which the answer can be inferred from the text. Cloze-style questions are an appealing form of such questions.
Task Description
The task consists of answering a cloze-style question, the answer to which depends on the understanding of a context document provided with the question. The model is also provided with a set of possible answers from which the correct one is to be selected.
- Dataset : CNN & Daily Mail & Children’s Book Test
Existing standard LSTM language models have human level performance on predicting verbs and prepositions, but they lack behind on named entities and common nouns. So, this paper focus only on predicting Named Entities & Common Nouns.
Model - Attention Sum Reader
Attention Sum Reader is tailor-made to leverage the fact that the answer is a word from the context document. There are clear advantages & disadvantages of this model. It’s performance on selecting the right answer under the setting mentioned above is outstanding, but it cannot produce an answer which is NOT contained in the document.
The model Structure is as follows (** Bidirectional) :
- Compute a vector embedding of the query
- Compute a vector embedding of each individual word in the context of the whole document (contextual embedding)
- Select the most likely answer using a dot product between the question embedding and the contextual embedding of each occurrence of a candidate answer in the document.
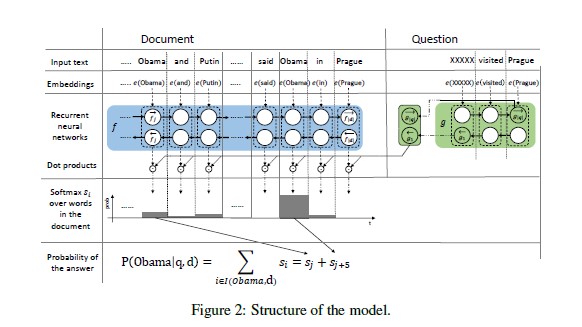
Detailed procedure :
- Word embedding : Translate words into vector representations
- First Encoder ( f ) : Encodes every word from the document in the context of the whole document (Document Encoder -> Contextual embedding)
- Second Encoder ( g ) : Translate the query into a fixed length representation of the same dimensionality as the output of first encoder
- Similarity : Compute a weight for every word in the document as the dot product of its contextual embedding & query embedding -> This weight might be viewed as an attention over the document
Formula :
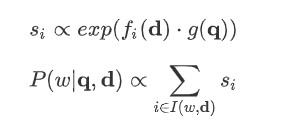
Pointer sum attention :
Note that I(w,d) above represents a set of positions where w appears in the document d. This mechanism is called pointer sum attention since it use attention as a pointer over discrete tokens in the contextual document and then directly sum the word’s attention across all the occurrences.
This differs from the usual use of attention in seq2seq models where attention is used to blend representations of words into a new embedding vector.
Model Comparison
1) Attentive and Impatient Readers
Fixed length representation r of the document d is as follows :
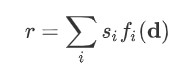
A joint query and document embedding m is then a non-linear function of r and the query embedding g(q). This joint embedding m is in the end compared against all candidate answers using the dot product, in the end the scores are normalized by softmax.
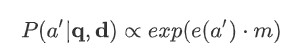
In contrast to above model, Attentive Sum Reader select the answer from the context directly using the computed attention rather than using such attention for a weighted sum of the individual representations.
For example, let’s consider the following sentence :
“A UFO was observed above our city in January and again in March“
Since both January and March are equally good candidates, the attention mechanism might put the same attention on both these candidates in the context. The blending mechanism described above would compute a vector between the representations of two words - January & March - and propose the closest word as the answer. This might be confusing. However, the proposed model would correctly propose January or March.
2) Chen et al. (2016)
Use bilinear term instead of simple dot-product.
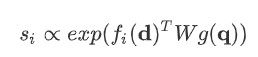
Other settings are similar to 1) above.
3) Memory Networks
Ex) Window-memory : uses windows of fixed length centered around the candidate words as memory cells. Due to this limited context window, the model is unable to capture dependencies out of scope of this window. Furthermore, the representation within such window is computed simply as the sum of embeddings of words in that window.
By contrast, in the proposed model the representation of each individual word is computed using a recurrent network, which not only allows it to capture context from the entire document but also the embedding computation is much more flexible than a simple sum.
ETC. - Dynamic Entity Representation, Pointer Networks ….
Reference
- https://arxiv.org/abs/1603.01547