
Explaining One Shot learning using Face Recognition
What is One Shot learning ?
One shot learning literally means learning to achieve the goal of the model given a single data. A typical example of this is face recognition. In order to perform Face Recognition, the model we have needs to be able to distinguish single face image entered as an input, since there is usually only one picture of an employee or team member in the database. This kind of task is what we call ‘one shot learning’. From now on, I will explain one-shot learning and other concepts based on the example of Face Recognition for simplicity.
One of the approaches is to add a class of employees and strangers to the softmax unit to learn. However, this is not enough to train the neural network, and when a new person joins the company, they have to add a softmax unit and retrain it, which is very cumbersome.
Another way we could think of is to let the model learn the similarity function. The neural network learns a function to obtain similarity between the two images, and when the new image is entered as an input, just calculate the similarity of the input and existing data to decide whether they are the same people.
We can use various similarity metrics such as cosine similarity, and express the general distance function as follows : d(img1, img2) = value (if this value is larger than pre-determined threshold, then two images are very different from each other).
From now on, let’s take a closer look on how we can perform one shot learning using similarity/distance function.
Siamese Network
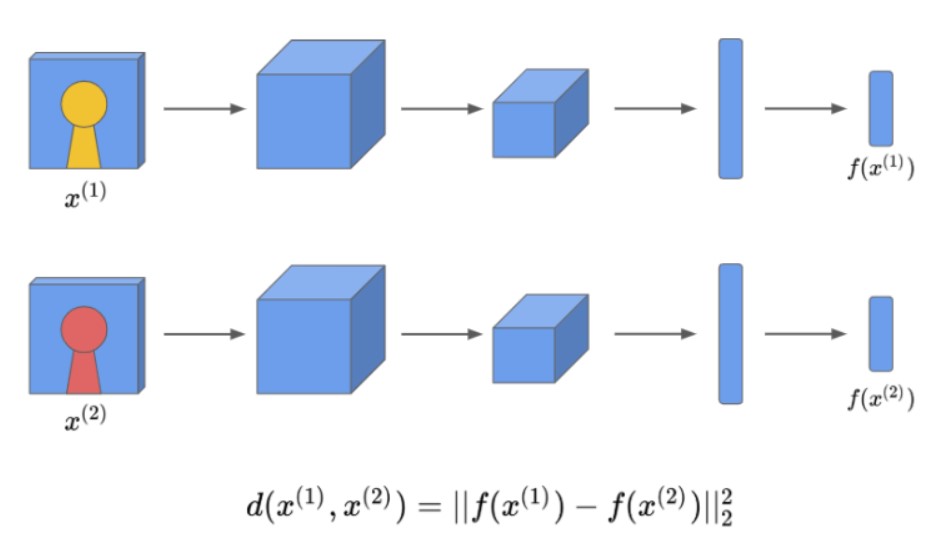
One way to learn a function through deep learning methods is by using Siamese network. Siamese network is a method published in CVPR in 2005, and two CNNs share weights. This CNN converts Image1 and Image2 to vector representation called f(image1) and f(image2), and weights are learned using the distance function.

Let’s dive deeper. To implement Siamese network in Face Recognition task, we should encode the input images into feature vectors. We can do this using CNN. If the two encoding vectors represent the image well, you can obtain the distance d between the two vectors. Here, we define the ‘distance’ as the norm between two vectors. Thus, in other words, the idea of running two convolutional neural networks independently for two inputs and then comparing them is called the Siamese network.
The learning procedure of Siamese network is as follows :
- Put two pictures into two networks as input and encode them with convolutional neural networks.
- If two people are similar, the distance value between encoding should be small. Similarly, the value of the distance between encoding should be large if two people are different.
- Train the model to meet the above conditions.
Then, at this point, you should have a question. So what do we use as loss function? The answer is, triplet loss.
Triplet Loss
To train Siamese network, we need to look at three images together - Anchor(A), Positive(P), Negative(N). A stands for the reference image, P stands for the image classified as A, and N stands for the image classified as different from A. Since we have to see three data at once, we call the loss used here a ‘triplet loss’.
Our purpose is to make the distance between A and P always less than or equal to the distance between A and N. This can be expressed as below.
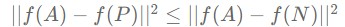
One obvious way to satisfy the above expression is to have both distances zero. Alternatively, it can be another way for all function values to have the same value. But these are not the directions we want. Therefore, to prevent neural networks from falling into these traps, neural networks must be informed that not all encodings are the same. To realize this, we add the margin alpha (hyperparameter) as shown below. The role of the margin is to make the difference between the two distances sufficient.
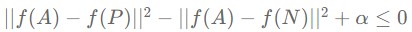
As a result, we can define the single & total triplet loss used in Siamese network as follows. FYI, the role of the max function here is to not care how negative the distance difference is (it’s more important to train the difference itself between A,P & A,N pairs than how far they are).
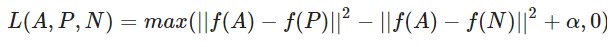
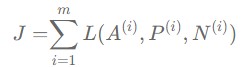
Selecting Triplets
Selecting training sets A, P, N at random makes it easy to achieve constraints, because two randomly selected photos A & N will be much different than A & P pair. That is, it is more probable for d(A,N) to be larger than d(A,P)+alpha if we select image samples randomly. When the constraint is satisfied easily, training the model through gradient descent method does not achieve high accuracy. In most cases, creating a training set that does not satisfy the constraint makes the gradient descent method work more efficiently. Therefore, you should make it difficult to learn when you make a training sets. How can we accomplish this?
If we can make d(A,P) and d(A,N) have similar values (-> difficult to satisfy the constraint), then it is a success. To do this, generate triplets online - select the hard positive/negative exemplars from within a mini-batch. hard positive exemplar indicates the positive exemplar which has the similar distance value (d(A,P)) to that of negative exemplar (d(A,N)). Rigorously, we should compute argmax and argmin of positive & negative exemplars across the whole training set, but it is infeasible. So, the authors of _FaceNet_ propose to select only hard _negatives_ and use all positive pairs in a _mini-batch_. In this way, we can select triplets that may help training the network efficiently with less computation.
In fact, there exists trade-off in determining the size of mini-batch. On the one hand we would like to use small mini-batches as these tend to improve convergence during SGD, but on the other hand implementation details make matches of 10s to 100s of exemplars more efficient. The main constraint with regards to the batch size is the way we select hard relevant triplets within the mini-batches. In FaceNet paper, it said batch size of around 1800 exemplars are used in most experiments.
Siamese Network with Binary classification (loss)
It is also possible to implement Face Recognition by formulating the issues with Binary classification. In this method, Siamese Network input both images and it is trained using the labels encoded the same person as 1 & the other person as 0. More detailed procedure is as follows :
- For both images, obtain the L1 vector of two representations that are passed through CNNs.
- Pass L1 vector through hidden layer and implement sigmoid conversion in output layer.
- Learn the model with Binary cross entropy as loss function.
- The model exports output with values between 0-1. This value is called “similarity” because the larger it is, the more similar the two images are.
- Through this process, CNN output representation for inputs have a small distance for the same person and a large distinction for the other person.
Formula :
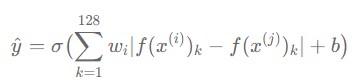
** The role of logistic is to determine whether the two images are the same person or not.
SO, by using Binary loss/classification instead of Triplet method, Siamese network can be trained and One Shot learning can be performed !!
Conclusion
So far, we’ve looked at One Shot learning, Siamese Network and Triplet loss through examples of Face Recognition. In addition to Face Recognition, One Shot Learning can be used in other areas of Computer Vision.. etc. In the next posting, I will explain about Few Shot Learning and Meta Learning.
Reference :
- https://www.cs.toronto.edu/~ranzato/publications/taigman_cvpr14.pdf
- https://arxiv.org/abs/1503.03832
- https://www.youtube.com/watch?v=d2XB5-tuCWU&feature=emb_title
- https://3months.tistory.com/507