
Today, we are going to know how to crawl iherb using Python, especially information about supplements.
Scheme
Before writing codes, it is important to decide which information is needed and how to store. In this example, assume that I want to collect supplements information for supplement-curating company. Basic information such as product names, images, prices, etc is definitely required and precise nutirion information might be helpful for that service (nutrition, amount, daily value).
Try to define your own scheme before moving on like this:
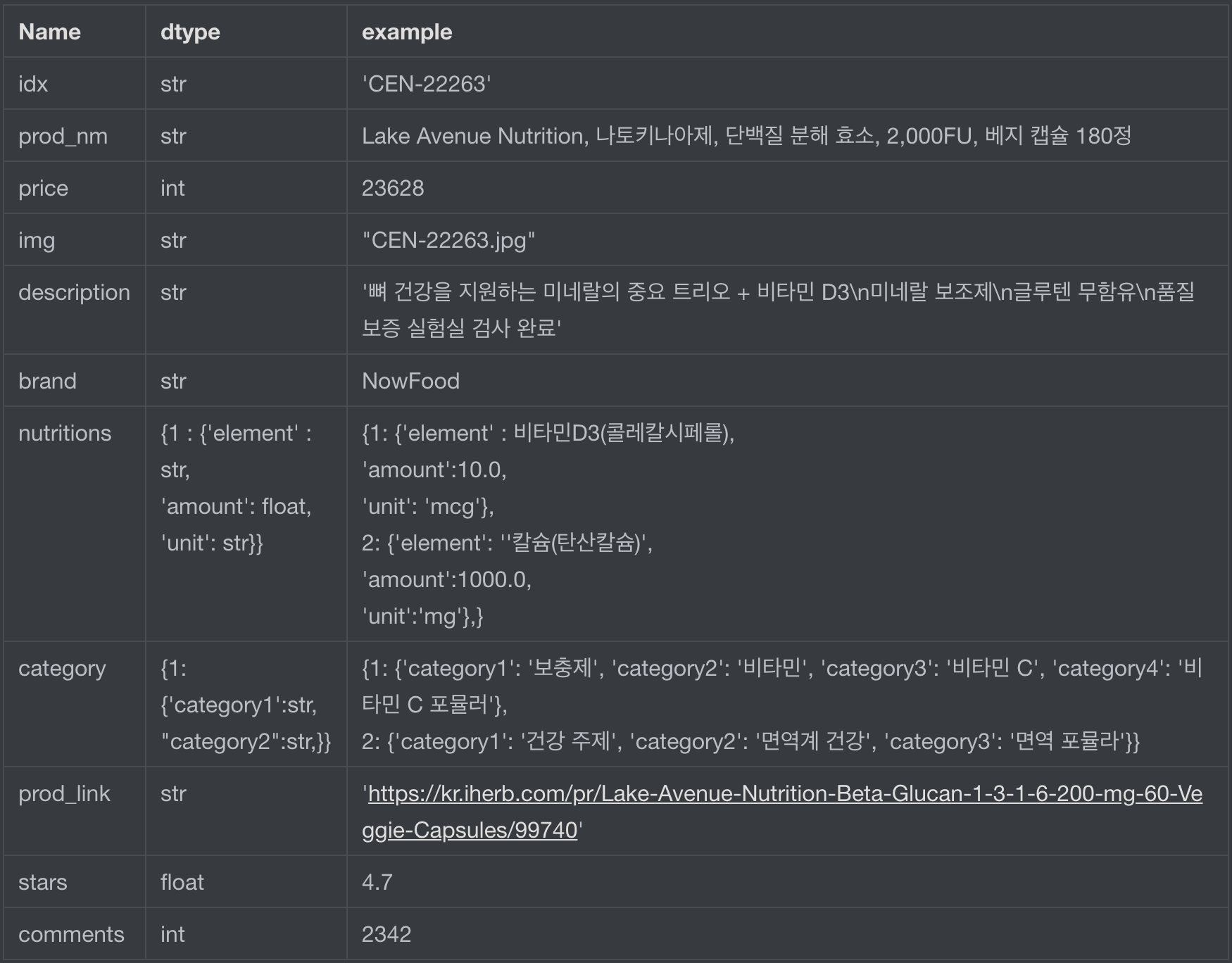
In many cases, we need to, for example, extract all the “element” information from “nutritions”, so it has better using dictionary type and set clear key values.
Code Implementation
Let’s start to crawl :fire:
First, import libraries
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import urllib.request
import requests
from bs4 import BeautifulSoup
import time
import numpy as np
import pandas as pd
import json
import re
import os
Below returns element located in ${selector}. We will use this to build get_details.
browser.find_element_by_css_selector(${selector}).text
def download_img(img, fname):
img_download_req = requests.get(img)
img_file = open(fname, "wb")
img_file.write(img_download_req.content)
img_file.close()
def get_nutrition_info(nutritions):
magic_word = ['영양소 기준치', 'DV','Daily Value', '일별 가치','Serving']
exit_word = ['권장량', '기준치', '습니다', '됩니다']
regex = re.compile(r'(?:mg|mcg|kg|ml|q.s.|ui|M|g|µg)')
x = nutritions.split('\n')[1:]
x = [val for val in x if not any(w in val for w in magic_word)]
x = [val for val in x if not any(w in val for w in exit_word)]
for i, val in enumerate(x):
if val.startswith('('):
x[(i-1):(i+1)] = [''.join(x[i-1:i+1])]
rtn = dict()
num_elem = 1
for elem in x:
elem = re.sub('(?<=\d)+ (?=\w)+', '', elem)
elem = re.sub('(?<=\D)+ (?=\D)+', '', elem)
elem = re.sub('(?<=\d)+ (?=\W)+', '', elem)
tmp = elem.split()
if len(tmp) > 1:
rtn[num_elem] = {}
if regex.search(tmp[-2])==None:
item = tmp[:-1]
amnt = tmp[-1]
try:
int_amnt = float(amnt[:regex.search(amnt).start()].replace(",",""))
except:
if amnt.isdigit():
amnt = int(amnt)
unit = None
else:
item = tmp
amnt = unit = None
else:
unit = regex.findall(amnt)[0]
amnt = int_amnt
else:
item = tmp[:-2]
amnt = tmp[-2]
try:
int_amnt = float(amnt[:regex.search(amnt).start()].replace(",",""))
except:
item = tmp
amnt = unit = None
else:
unit = regex.findall(amnt)[0]
amnt = int_amnt
rtn[num_elem]['element'] = " ".join(item)
rtn[num_elem]['amount'] = amnt
rtn[num_elem]['unit'] = unit
num_elem += 1
return rtn
def get_details(product_url, rtn):
browser.get(product_url)
prod_idx = browser.find_element_by_css_selector("#product-specs-list > li:nth-child(4) > span").text
prod_nm = browser.find_element_by_css_selector("#name").text
price = browser.find_element_by_css_selector("#price").text
img = browser.find_element_by_css_selector("#iherb-product-image").get_attribute("src")
brand_category = browser.find_element_by_id("breadCrumbs")
a_tag = brand_category.find_elements_by_tag_name('a')
try:
review_cnt = browser.find_element_by_css_selector('#product-summary-header > div.rating > a.rating-count > span').text
except:
review_cnt = 0
try:
stars = float(browser.find_element_by_css_selector('#product-reviews > div > div.content-frame.product-details-reviews > section > div.inner-content > div > div.featured-reviews.row > div > div:nth-child(1) > div > div > div.css-i36p8g').text)
except:
stars = None
try:
brand = browser.find_element_by_css_selector('#breadCrumbs > a:nth-child(2)').text
except:
brand = None
try:
category = find_category(a_tag)
except:
category = None
try:
description = browser.find_element_by_css_selector("body > div.product-grouping-wrapper.defer-block > article > div.container.product-overview > div > section > div.inner-content > div > div > div.col-xs-24.col-md-14 > div:nth-child(1) > div > div > ul")\
.text.replace("\n", " ")
except:
description = None
try:
nutritions = browser.find_element_by_css_selector('body > div.product-grouping-wrapper.defer-block > article > div.container.product-overview > div > section > div.inner-content > div > div > div.col-xs-24.col-md-10 > div').text
except:
nutritions = None
# download image
fname = str(prod_idx)+".jpg"
download_img(img, fname)
rtn.append({
'idx':prod_idx,
'prod_nm':prod_nm,
'price':int(price[1:].replace(',','')),
'review_cnt':int(review_cnt),
'stars':stars,
'brand':brand,
'img':fname,
'category':category,
'description':description,
'nutritions':get_nutrition_info(nutritions),
'prod_link':product_url,
})
return rtn
As you can see, try and except are frequently used since some products’ information has not been updated yet. We should consider all these exceptions:bulb:
So, how to get ${selector} ?
Go to iHerb website and open developer tool - Option+Ctrl+I in Mac. With the blue cursor icon on top of the developer tool, you can directly point out the location you want to extract information from. In the image below, I locate the cursor on the price area so the related part in the developer tool is shaded out.
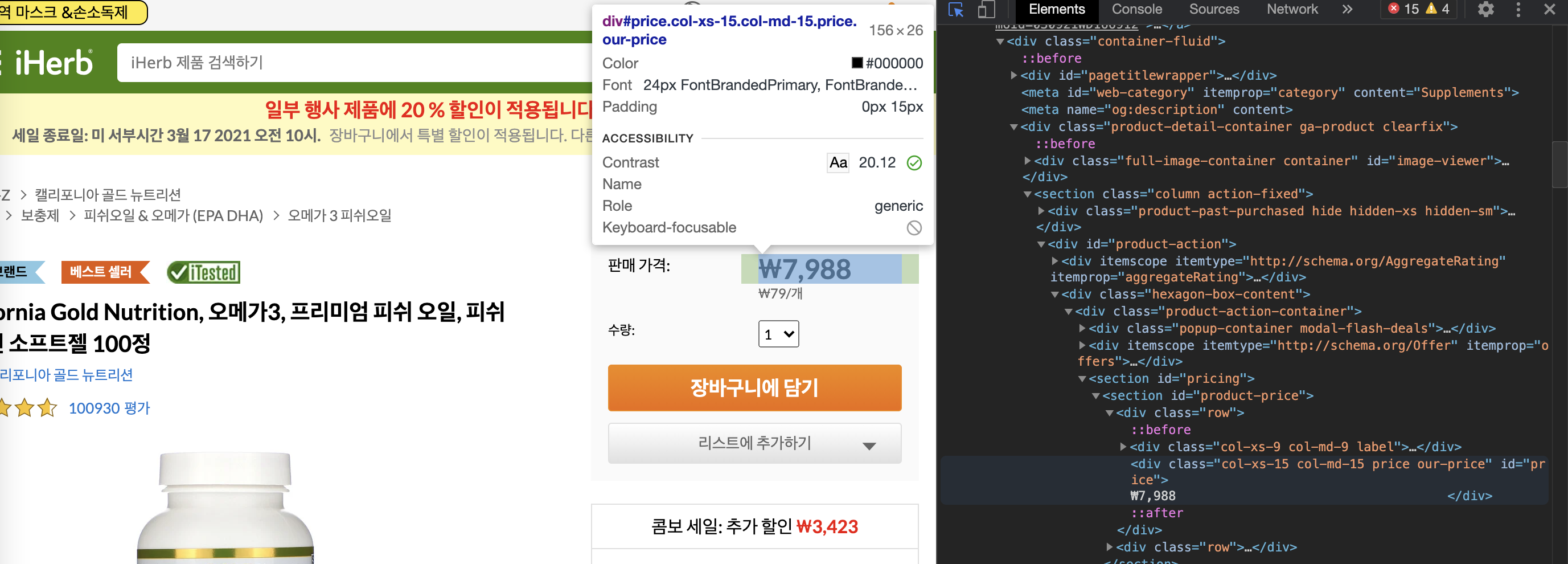
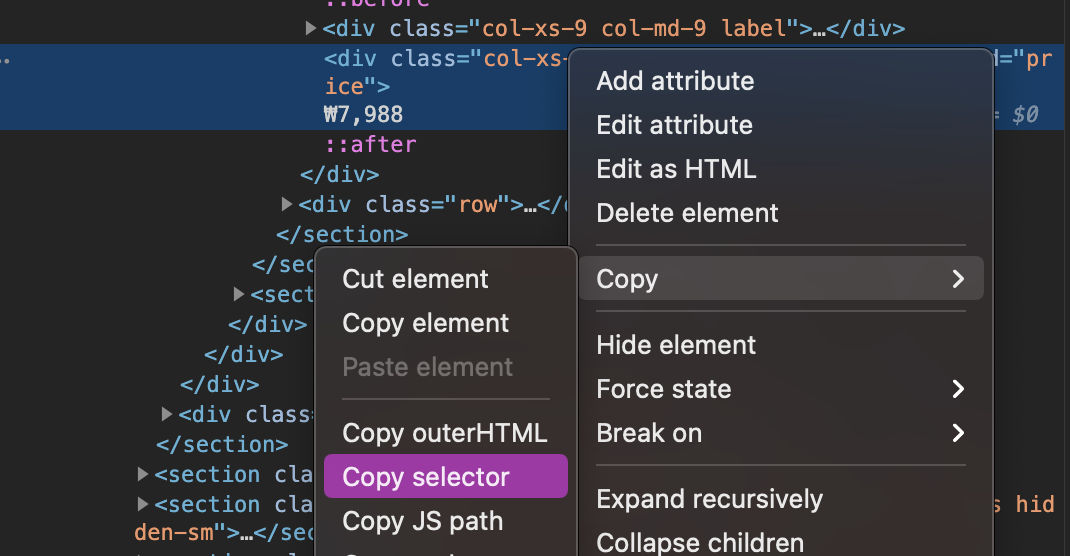
Copy the selected area’s selector. It works like an address of “price”, informing our crawling machine that “price” information is here!.
Some utility functions to convert extracted data into right format.
def download_img(img, fname):
img_download_req = requests.get(img)
img_file = open(fname, "wb")
img_file.write(img_download_req.content)
img_file.close()
def get_nutrition_info(nutritions):
magic_word = ['영양소 기준치', 'DV','Daily Value', '일별 가치','Serving']
exit_word = ['권장량', '기준치', '습니다', '됩니다']
regex = re.compile(r'(?:mg|mcg|kg|ml|q.s.|ui|M|g|µg)')
x = nutritions.split('\n')[1:]
x = [val for val in x if not any(w in val for w in magic_word)]
x = [val for val in x if not any(w in val for w in exit_word)]
for i, val in enumerate(x):
if val.startswith('('):
x[(i-1):(i+1)] = [''.join(x[i-1:i+1])]
rtn = dict()
num_elem = 1
for elem in x:
elem = re.sub('(?<=\d)+ (?=\w)+', '', elem)
elem = re.sub('(?<=\D)+ (?=\D)+', '', elem)
elem = re.sub('(?<=\d)+ (?=\W)+', '', elem)
tmp = elem.split()
if len(tmp) > 1:
rtn[num_elem] = {}
if regex.search(tmp[-2])==None:
item = tmp[:-1]
amnt = tmp[-1]
try:
int_amnt = float(amnt[:regex.search(amnt).start()].replace(",",""))
except:
if amnt.isdigit():
amnt = int(amnt)
unit = None
else:
item = tmp
amnt = unit = None
else:
unit = regex.findall(amnt)[0]
amnt = int_amnt
else:
item = tmp[:-2]
amnt = tmp[-2]
try:
int_amnt = float(amnt[:regex.search(amnt).start()].replace(",",""))
except:
item = tmp
amnt = unit = None
else:
unit = regex.findall(amnt)[0]
amnt = int_amnt
rtn[num_elem]['element'] = " ".join(item)
rtn[num_elem]['amount'] = amnt
rtn[num_elem]['unit'] = unit
num_elem += 1
return rtn
def find_category(a_tag):
rtn = {}
category_num = 1
key = 0
for i in range(2, len(a_tag)):
if a_tag[i].text == "카테고리":
key += 1
category_num = 1
rtn[key] = {}
continue
rtn[key]["category"+str(category_num)] = a_tag[i].text
category_num += 1
return rtn
get_nutrition_info function might seem a bit complex, lots of regex and conditions. Remind that we should prevent all these exceptions!
Since it takes a while to finish crawling, it is better to crawl all the information and then process data rather than trying to subtract and process it while crawling.
def crawl_n_pages(target_url='https://kr.iherb.com/c/supplements?sr=10',
from_page = 1, to_page = 3):
# load from the saved file
if os.path.exists('iherb_supp_crawling.json'):
with open('iherb_supp_crawling.json', 'r', encoding="utf-8") as f:
json_data = json.load(f)
data = json_data
prod_list = [item['idx'] for item in json_data]
else:
data, prod_list = [], []
chrome_driver_path = ${chrome_driver_path}
options=webdriver.ChromeOptions()
options.add_argument(${user agent information})
options.add_argument('--no-sandbox')
browser = webdriver.Chrome(chrome_driver_path, options = options)
for i in range(from_page, to_page+1):
pages = 1
supp_page_urls=[]
browser.get(target_url+"&p=%d" % i)
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
prod_url=soup.find_all("a",{'class':"absolute-link product-link"})
for j, url_tag in enumerate(prod_url):
if url_tag['data-part-number'] in prod_list:
print("-----------already collected----------")
pass
else:
print(url_tag['href'])
data = get_details(url_tag['href'], data)
pages += 1
if pages % 10 == 0:
# save as json file
file_name = 'iherb_supp_crawling.json'
with open(file_name, 'w', encoding='UTF-8') as f:
json.dump(data, f, ensure_ascii=False)
print("json file has been saved!")
time.sleep(2)
:bulb: Web-crawling process is often stopped unexpectedly, so we’d better save crawled data regularly and include loading saved file (crawled) to skip already collected data. In crawl_n_pages, I set from_page and to_page arguments, letting the function to crawl from the second page to 4th page (below code). This is helpful as we tend to run the crawling process simultaneously using multiple kernels.
Remember that crawling process is quite time consuming, with tons of exceptions :cry:
crawl_n_pages(from_page=2, to_page=4)