
How to make “text” to be input in deep learning?
Can deep learning input text like “github”, “blog”?
No. We should convert text to numbers that deep learning can understand.
Converting text to numbers? Probably reminds you “one-hot encoding” but in Natural Language Processing (NLP), encoding is not useful since we cannot calculate similarities between words - all the distances between words are the same.
That’s why word embedding is important.
Embedding
Embedding is a dense vector with similarity, which has lower dimension that one-hot encoding generally.
Word2Vec
is the most famous word embedding method, proposed in 2013. Word2Vec utilizes neighboring words of target words. Before going over examples of word embeddings, I want to mention that the original paper suggests four different model architecture but I am going to cover only Skip-Gram since the quality of embedding is better as we can generate more training dataset. Skip-gram predicts neighboring words based on the current word.
What “generating more training dataset” means?
Assume that we have a source text like “I ate hamburgers this morning” and w = 2. Then the pair of x and y is only one for each y, ({I, ate, this, morning}, hamburgers) when y = “hamburgers”, in Continuous Bag-of-Words Model, another embedding method that predict the current word based on context in the same sentence. In Skip-Gram, however, there are four pairs for each target “hamburgers”, (hamburgers, I), (hamburgers, ate), (hamburgers, this), (hamburgers, morning) in this example. This process gives the model more opportunities to update weights.
See how Skip-Gram looks like:
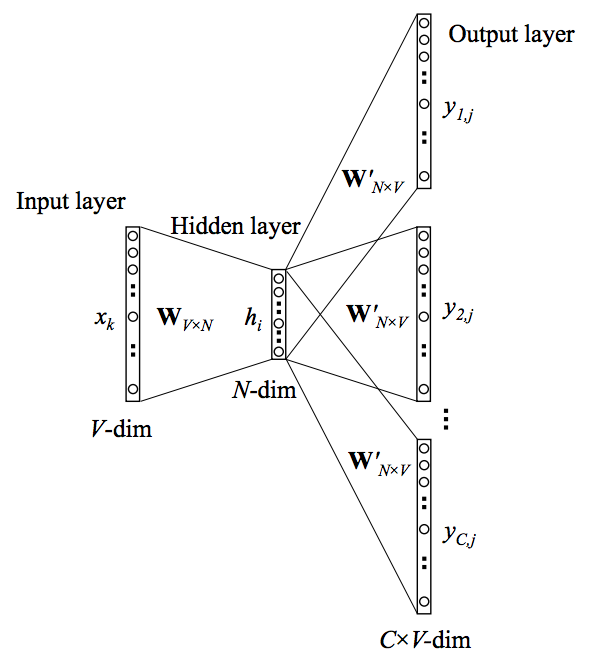
So, let’s go back to word2vec. The example is from this video.
For example, we have two sentences: “king brave man”, “queen beautiful woman” after preprocessing. Then, by the definition of Skip-gram, the input and target data is:
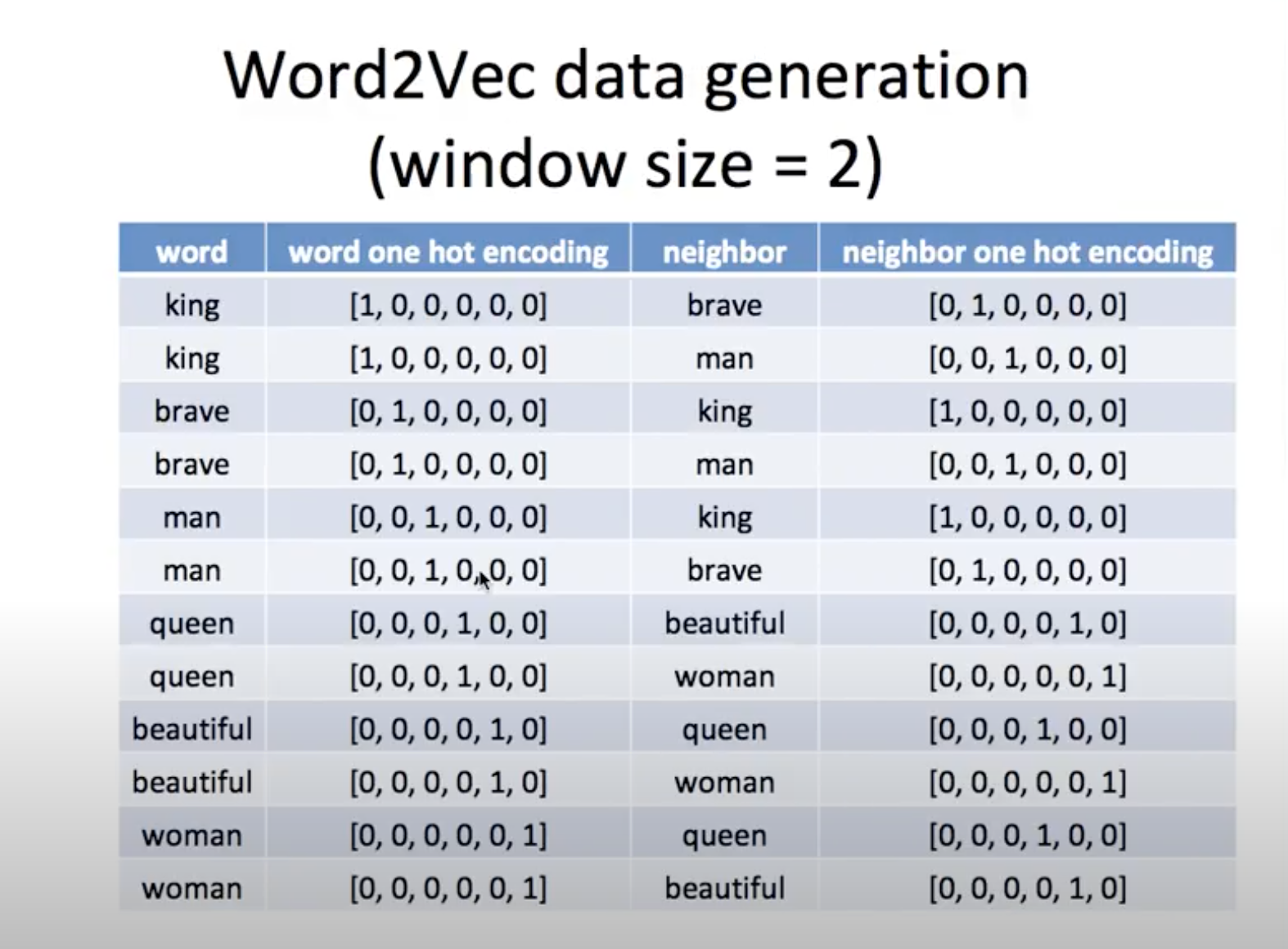
where the first column is the neighboring (t-2, t-1, t+1 or t+2) word and the third column is the current word (at t). The second column is encoded version of the first one, which will be input of our model and the fourth column is encoded version of the third column to be the actual output.
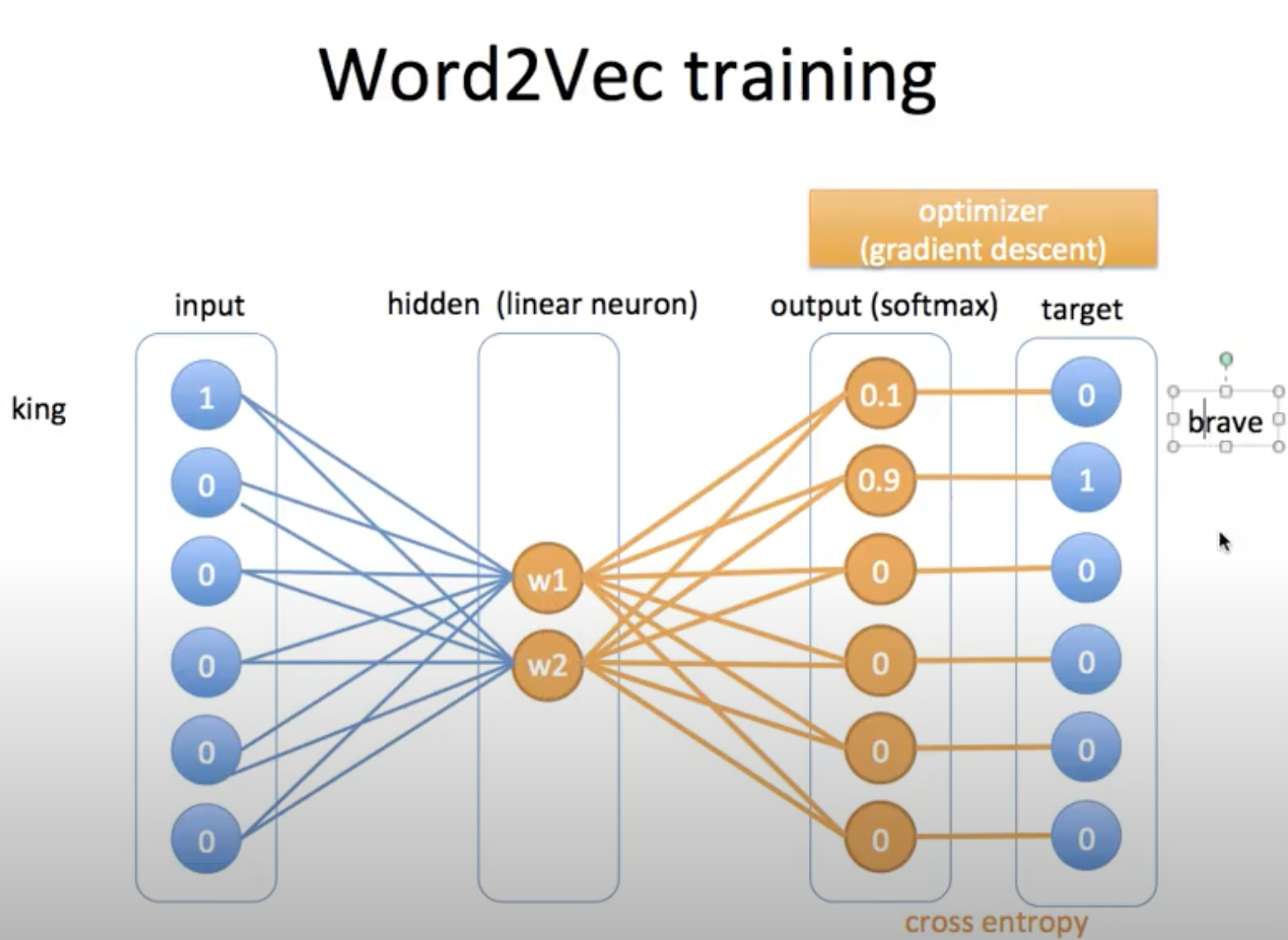
Parameters are updated to learn similarities between words, ending up being a collection of embedding words, Word2Vec. How?
See the figure below,
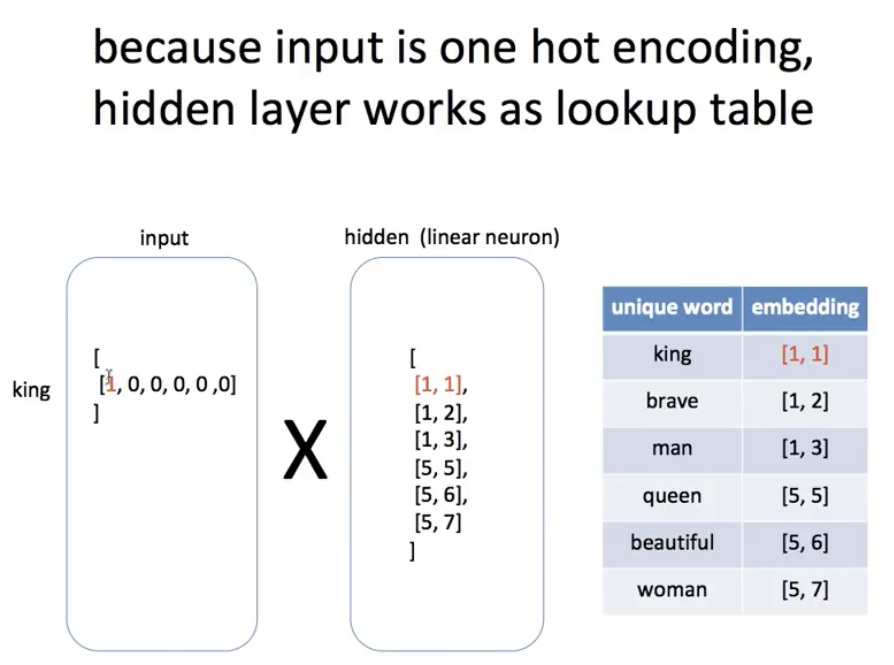
Since the input is one-hot encoded, processing the hidden layer actually works as a lookup table - lookup the row vector of the weight matrix W for the current value. The hidden layer values, thus, becomes a collection of word2vec embedding. With this embedding values, we can calculate similarities between words.
The below graph illustrates words’ similarities when the corpus is
'he is a king',
'she is a queen',
'he is a man',
'she is a woman',
'warsaw is poland capital',
'berlin is germany capital',
'paris is france capital'

Wevi provides an interesting visulization tool. Check :)