
R-CNN, Fast R-CNN, Fast R-CNN are two-stage object detector: generate region proposals then execute classification.
YOLO (You Look Only Once) is a one-stage object detector that simultaneously processing two.
Advantages over two-stage models:
- fast!
- sees the whole image during training, conserving not only object appearance but contextual information
- generalization - even outperforms R-CNN
However, compared to other two-stage object detection methods, it performs poor in accuracy. Depending on the aim of your project, we should consider these aspects carefully.
Then, how it works?
Assume that we have an input like this.

Divides the input into an S × S grid. Each grid cell predicts B bounding boxes and scores confidence, where confidence, equivalently,
$ \operatorname{Pr}(\text { Object }) * \text { IOU }_{\text {pred }}^{\text {truth }} $
and this reflect how confident the model is on the objectness and how accurate the predicted box is.

Thus, each bounding box outputs five values, four coordinates and the confidence.
Also, the model predicts a class for each grid cell.
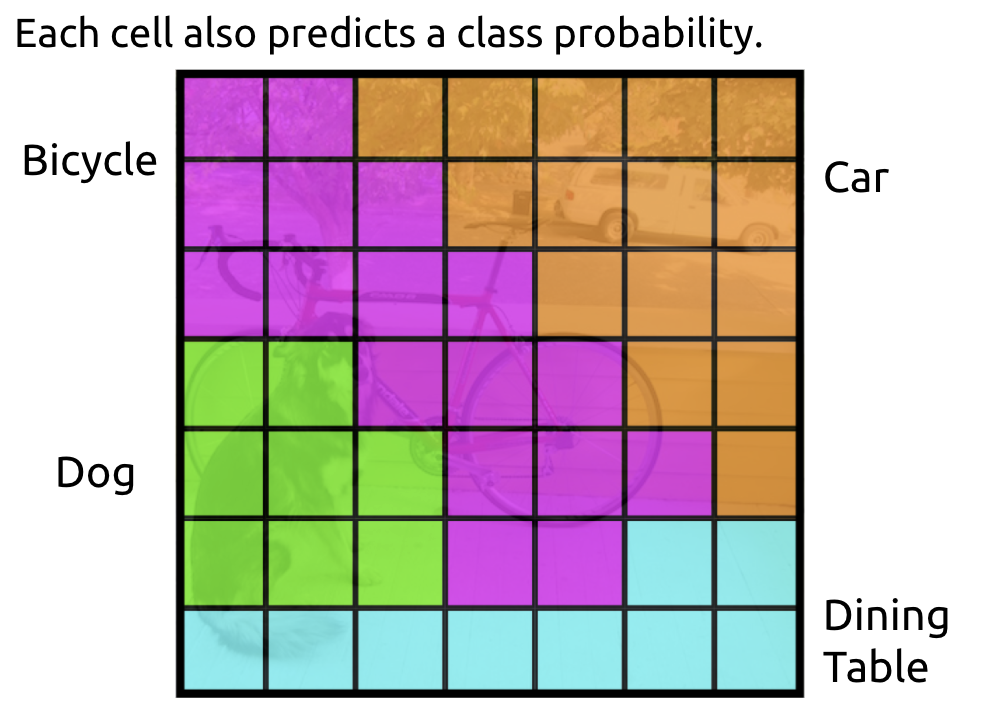
Combining the classification and predicted box coordinates, the output would be:

More specifically, we define class-specific confidence scores for each box,
\[\operatorname{Pr}\left(\text { Class }_{i} \mid \text { Object }\right) * \operatorname{Pr}(\text { Object }) * \text { IOU }_{\text {pred }}^{\text {truth }}=\operatorname{Pr}\left(\text { Class }_{i}\right) * \text { IOU }_{\text {pred }}^{\text {truth }}\]and for large objects that cannot be located within the predicted box or some exceptional cases, we run Non-Maximal Suppression (NMS) to group out multiple boxes.
Finally,

YOLO can predict on bounding box and classification at one stage by running through the below model architecture!
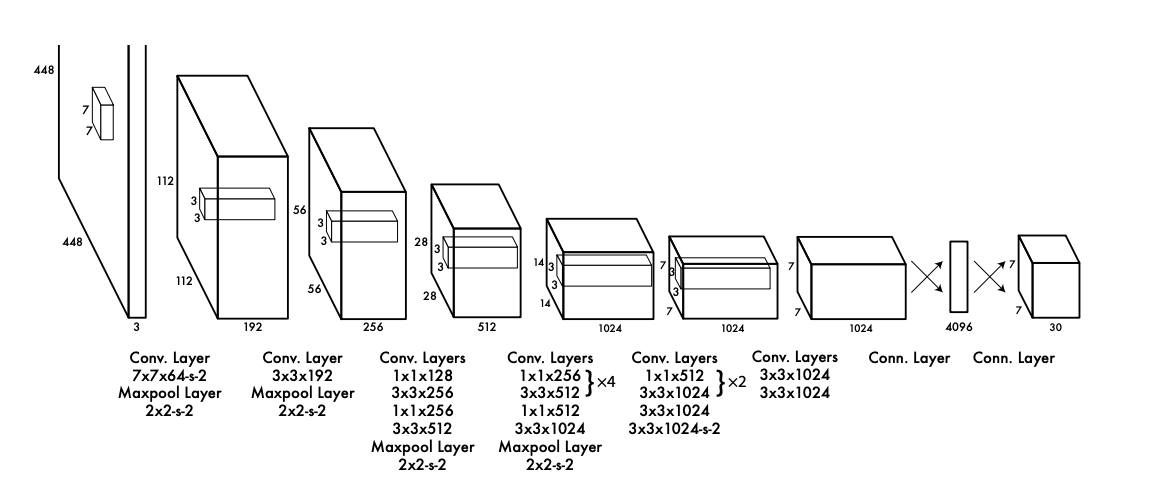
As you see, the output is 7 x 7 x 30, where the grid size is 7 x 7 and five output values for B bounding boxes (B=2 in this paper) plus 20 categories. 7 x 7 x (5x2 + 20). Clear :)
Additionally, YOLO has another limitation that it only predicts one class for each grid cell. This means that it is likely to miss information if there are multiple objects with different classes within a grid.
I’ll cover later papers and check how people solve these limitations eventually next time :fire: